tiny-cuda-nn使用
一.概括
这是一个用于训练和查询神经网络的小型自包含框架。值得一提的是,它包含一个闪电般的快速“完全融合”多层感知器,一个通用的多分辨率哈希编码,以及对各种其他输入编码、损失和优化器的支持。
1. “完全融合”多层感知器
图来自Real-time Neural Radiance Caching for Path Tracing (tom94.net)
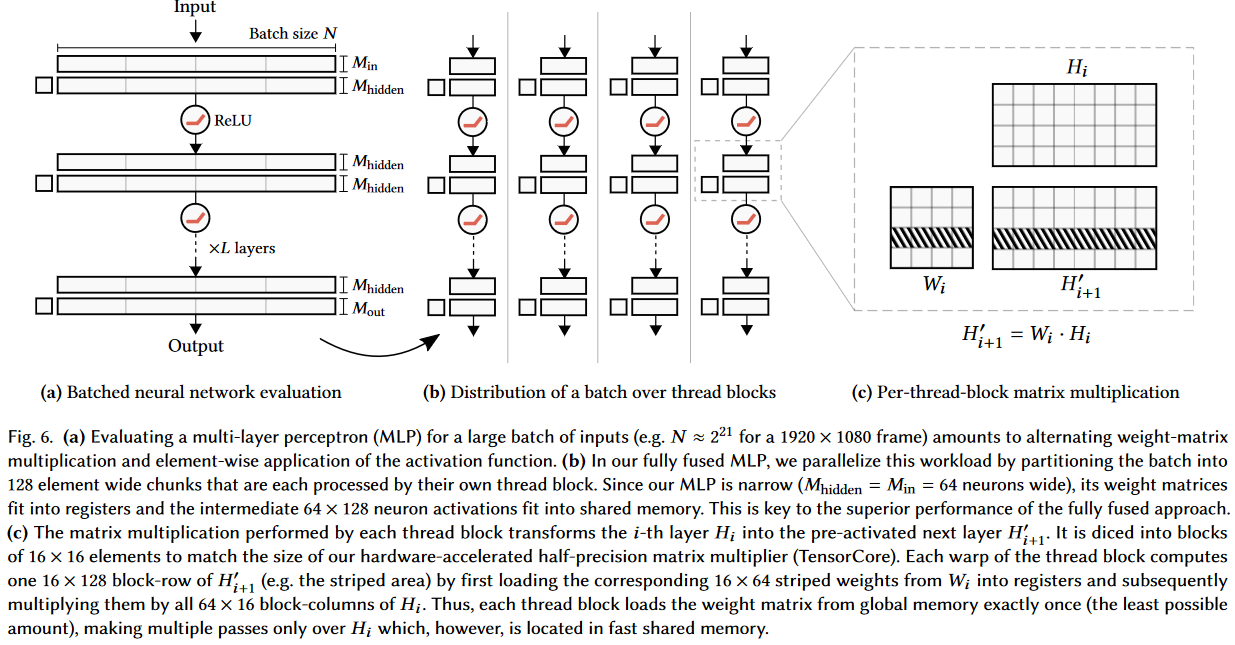
(a)对于大批量输入(例如对于1920 × 1080帧,N≈\(2^{21}\)),评估多层感知器(MLP)相当于交替使用“权矩阵乘法”和“激活函数的按元素应用”。
(b)在我们的完全融合MLP中,我们通过将批划分为128个元素宽的块来并行化这个工作负载,每个块由各自的线程块处理。由于我们的MLP很窄(\(M_{hidden}\) = \(M_{in}\) = 64个神经元宽),它的权重矩阵适合寄存器,中间的64 × 128个神经元激活适合共享内存。这是完全融合方法的卓越性能的关键。
(c)每个线程块进行矩阵乘法运算,将第i层\(H_{i}\)转换为预先激活的下一层\(H^{'}_{i+1}\)。它被切成16 × 16个元素的块,以匹配我们的硬件加速的半精度矩阵乘法器(TensorCore)的大小。每个线程块的组计算一个16 × 128块行\(H^{'}_{i+1}\)(例如条带区域),首先从\(W_i\)加载相应的16 × 64条带权重到寄存器,然后将它们乘以\(H_{i}\)的所有64 × 16块列。因此,每个线程块只从全局内存加载一次权值矩阵(尽可能少的量),只在位于快速共享内存中的Hi上进行多次传递。
2. 多分辨率哈希编码
图来自Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (nvlabs.github.io)
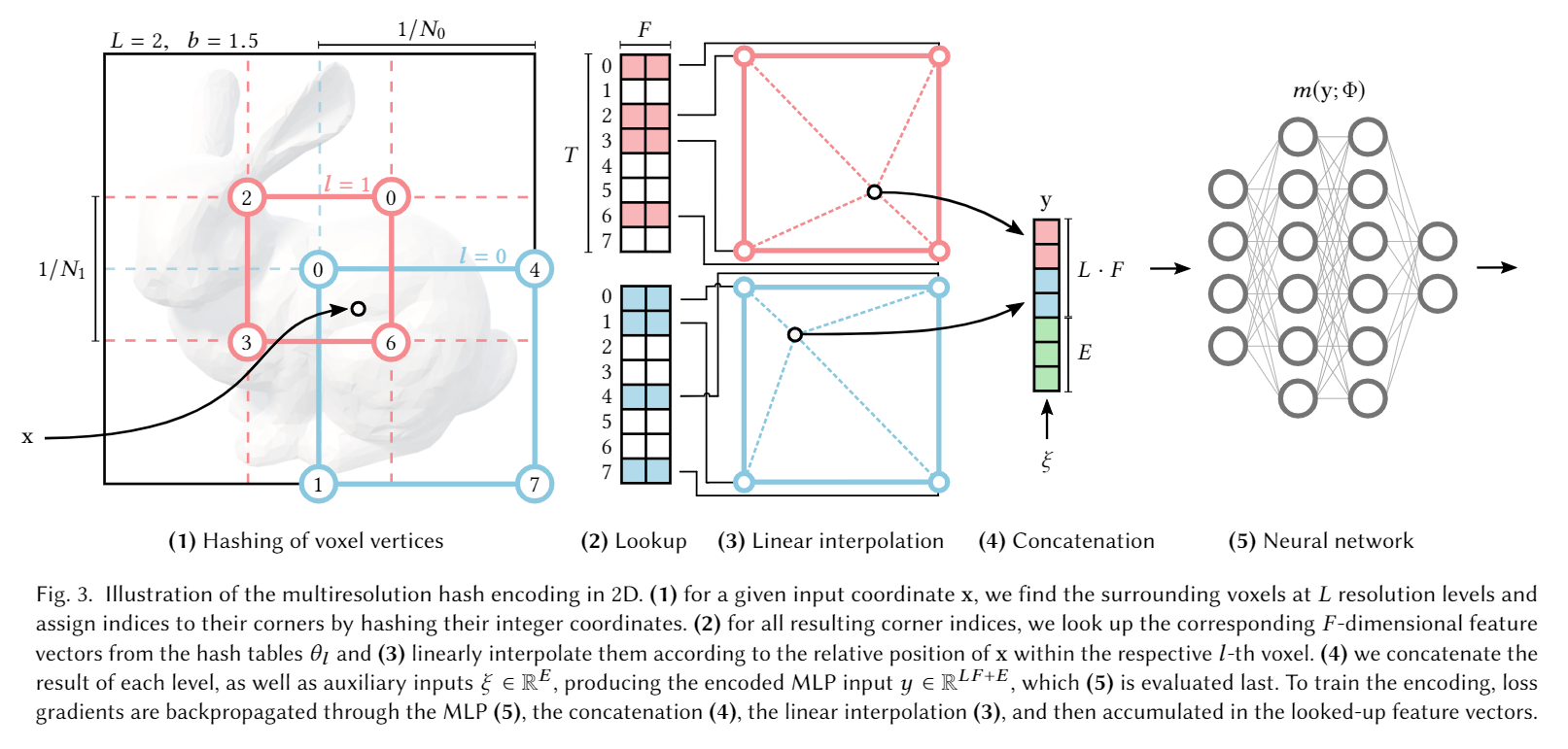
(算法流程序号和图中序号无关)
1)L是分辨率级数(一般取16,即有16个不同级别分辨率的哈希表作为辅助结构)。对于输入坐标x,我们在每一个分辨率级别上找到它周围的体素,并通过哈希它们的整数坐标为它们的角指定索引。
2)对于得到的角索引,我们从哈希表查询相关的F维(一般取F=2)特征向量,根据坐标x和体素的相对位置进行线性插值,得到x的特征向量。
3)将每一个分辨率级别上得出的x特征向量进行拼接,同时拼接入辅助输入ξ(维度为E)。此时得到的输出的维度一共是L·F+E。
4)将输入进行编码后输入MLP进行训练。损失梯度会通过MLP、向量拼接、线性插值传播,然后累计到查找的特征向量上。
二.表现

Fully fused networks vs. TensorFlow v2.5.0 w/ XLA。
在RTX 3090上测量64个(实线)和128个(虚线)神经元宽的多层感知器。由benchmarks/bench_ours. cu和使用 data/config_oneblob.json的benchmarks/bench_tensorflow.py生成。
三.用法
简单的C++/CUDA API:
1 | |
也可以直接在pytorch里使用。