复现纪要
初学时记录一些简单的复现,后不再更新。
复现NeRF
Mildenhall B , Srinivasan P P , Tancik M , et al. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis[J]. Springer, Cham, 2020.
1. 运行环境
1.1 ubuntu
1.1.1 软硬件
设备:华硕魔霸新锐2021
系统:Ubuntu 21.10
显卡:NVIDIA GeForce RTX 3060 Laptop GPU
python环境:(与项目原环境不同)
conda
1 | |
tensorflow-gpu==2.5.0也可以通过pip install tensorflow-gpu==2.5.0 (-i https://pypi.doubanio.com/simple ,指定安装渠道) 安装。
1.1.2 备注
该项目的依赖imagemagick仅有linux和osx版本,没有windows版本,因此使用ubuntu。
Ubuntu 21.10 之前的LTS版本没有合适此设备的键盘驱动和WIFI驱动。
3060只支持cuda11.1版本及以上,不兼容tensorflow1及相应cuda,运行项目会报错误(类似问题),因此使用tensorflow2(参考)。
由于使用tensorflow2,以脚本为主、手工为辅的方式(参考)将原代码由tensorflow1改造升级到tensorflow2。
发现在conda中安装cudatoolkit和cudnn会找不到3060,因此手动安装(参考)。采用cudnn 8.1+cuda 11.2。nvdia-smi显示cuda版本大于等于nvcc显示的cuda版本即可。
tensorflow-gpu==2.5.0不可使用conda安装,单独安装(参考)
测试gpu
1
2import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))关闭ubuntu的合盖挂起。在使用GPU训练的时候如果挂机会导致nvidia驱动损坏,无法使用nvidia-smi,需要重装nvidia驱动(但不影响nvcc)。如果使用nvidia官方的驱动重装非常麻烦,并且可能会导致开机黑屏的bug,此刻需要进入ubuntu高级选项-恢复模式,通过root进入命令行,卸载nvidia驱动(直接使用命令卸载可能卸载不掉,需要使用nvidia驱动的安装文件卸载)。所以推荐使用标准ubuntu仓库进行驱动的自动安装。
1
2
3sudo ubuntu-drivers devices
sudo ubuntu-drivers autoinstall
sudo reboot
1.2 windows
1.2.1 软硬件
设备:华硕魔霸新锐2021
系统:windows 10
显卡:NVIDIA GeForce RTX 3060 Laptop GPU
python环境:(与项目原环境不同)
conda
1 | |
1.2.2 备注
- windows10中需安装好cudnn 8.1+cuda 11.2。
- 代码需要升级到tensorflow2。
- 相比在ubuntu中配置环境时去掉了原作者的imagemagick依赖。可以正常训练。
- 在conda中激活建立好的nerf2环境后,使用命令python run_nerf_RE.py --config ./configs/config_fern.txt开启训练fern模型。
2.实际运行
2.1 本地验证
复现使用作者的原代码,在这里使用python run_nerf.py --config config_fern.txt 运行fern demo。(没有使用paper_configs里的llff_config,使用的作者提供的简化版config_fern.txt)
如果直接使用原来的参数运行,由于训练规模过大,在训练一定轮次后,会报显存不够的错误:
tensorflow.python.framework.errors_impl.ResourceExhaustedError: OOM when allocating tensor with shape[4194304,90] and type float on /job:localhost/replica:0/task:0/device:GPU:0 by allocator GPU_0_bfc [Op:ConcatV2] name: concat
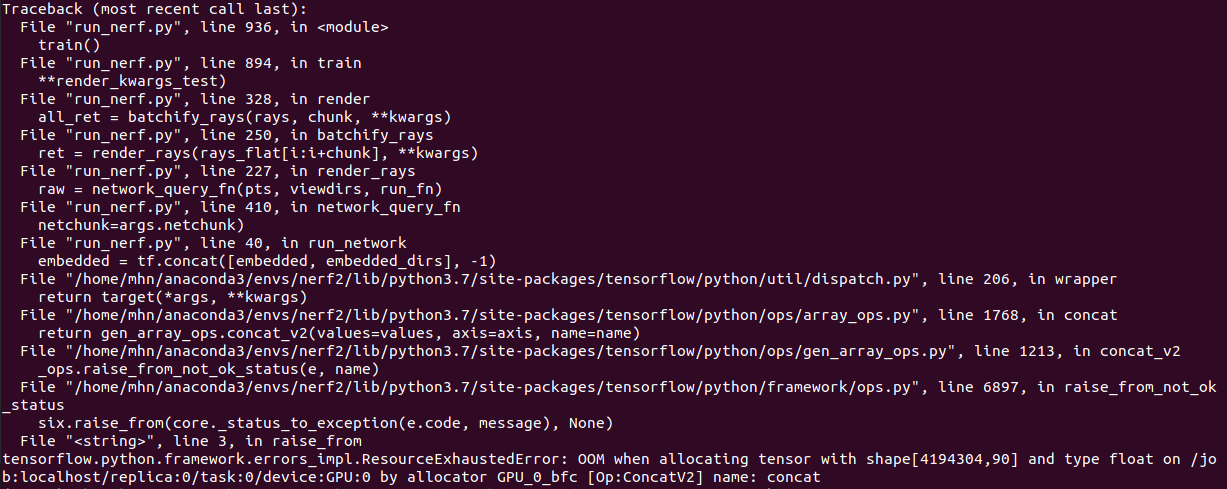
应该是因为我的3060的6G显存不如作者使用的nvidia v100。
因此,将config_fern.txt中的参数由:
1 | |
降低为:
1 | |
以减小训练规模,然后可以正常训练。
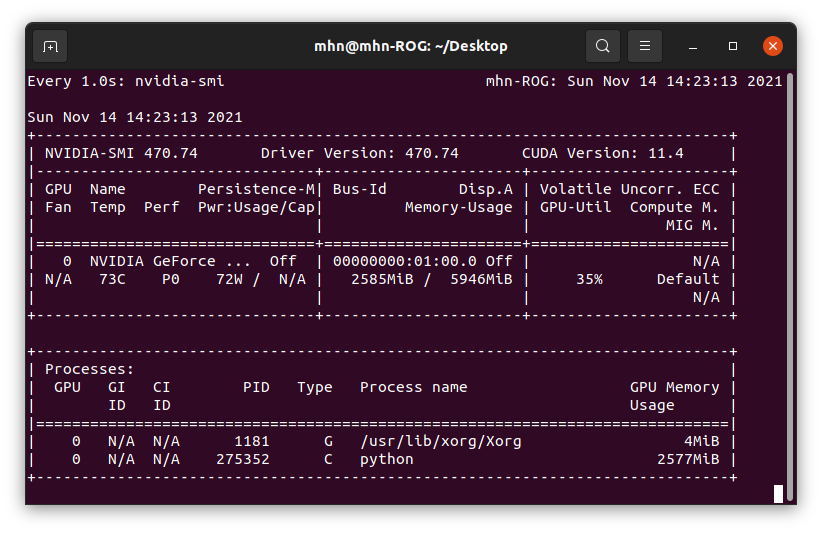
实际运行中的GPU情况:
Terminal输出:
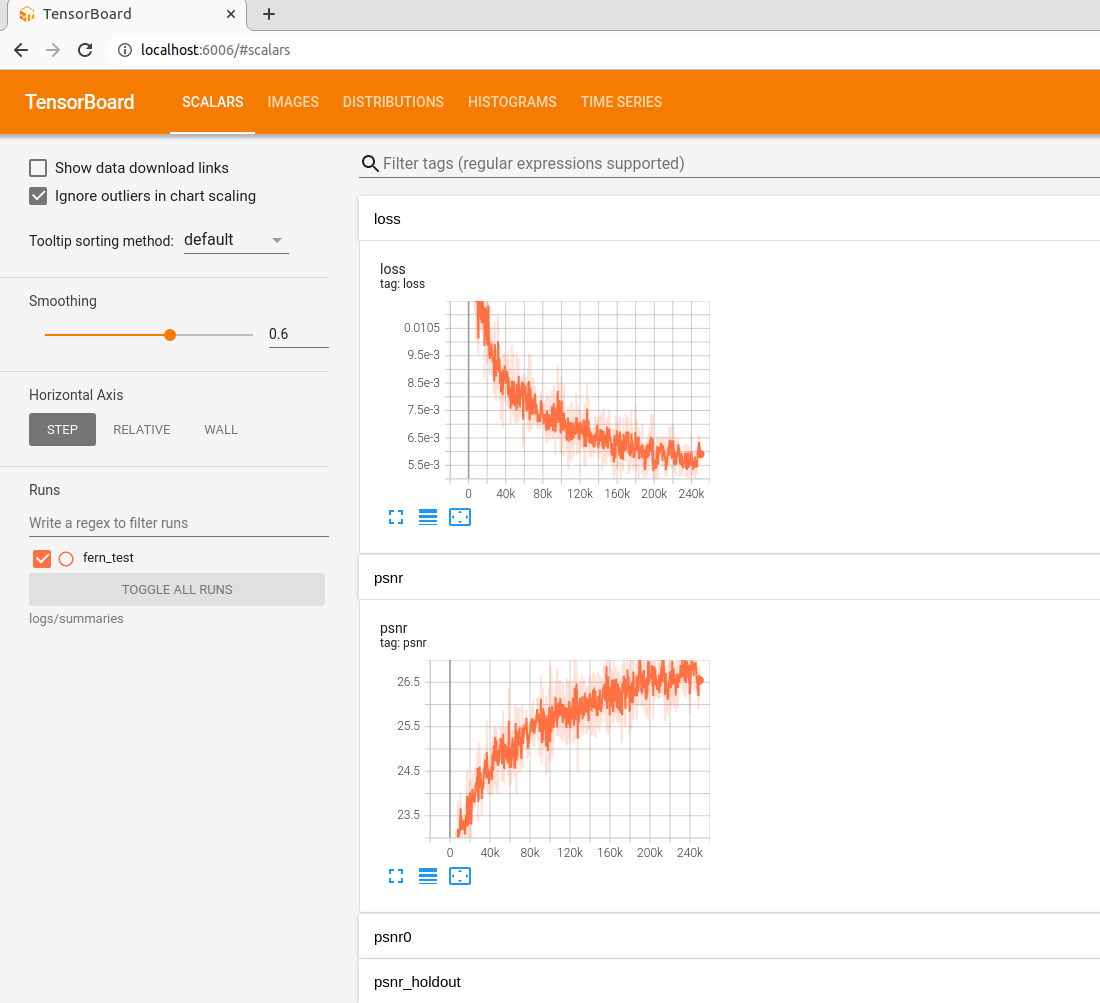
tesnorboard输出:
使用命令tensorboard --logdir=logs/summaries --port=6006,查看网页

最后输出的视频位于logs/fern_test文件夹中
完成整个训练过程大概需要34个小时(跑完1000k iterations,没有收敛)。因此减小训练参数效果不好。
2.2 复现论文
因为在本地6G显存的3060上无法复现论文,所以采用24G的3090进行复现。
3060与3090可以使用完全相同的环境。
实际复现时使用了17G显存,迭代了200k次,大概24个小时。PSNR达到了论文的效果。
2.3 训练细节
llff类型数据:
使用手机拍摄20张以上的照片,使用colmap自动生成相机参数。
我使用的是和作者一个型号的手机,因此拍照照片大小一样,均为4096*3024。拍完后分别做四分之一降采样和八分之一降采样的照片备用。作者在论文中使用的是四分之一降采样的照片做训练。
要求图片的长宽是16的整数倍,否则网络会做裁剪处理,可能会导致损失增大。
手动拍摄的照片之间基线不能太宽,角度变化不能太大。
1 | |
3.代码分析
以实际运行的fern demo为例子
3.1 输入参数列表
| 参数名 | 默认值 | 作用 |
|---|---|---|
| config | 配置文件路径 | |
| expname | 实验名 | |
| basedir | ./logs/ | 存放ckpts和logs的路径 |
| datadir | ./data/llff/fern | 输入数据路径 |
| netdepth | 8 | 网络层数 |
| netwidth | 256 | 每层的通道数 |
| N_rand | 32*32*4 | 批大小 (每一梯度步的随即光线数) |
| lrate | 5e-4 | 学习率 |
| lrate_decay | 250 | 指数学习率下降(1000s内) |
| chunk | 1024*32 | 平行处理的光线数(内存不足时应减小) |
| netchunk | 1024*64 | 网络里平行发送的pts数(内存不足时应减小) |
| no_batching | False | 一次只从一张图片获取随机光线 |
| no_reload | False | 不从保存的模型中重载权重 |
| ft_path | None | 专为coarse网络重载的权重npy文件 |
| random_seed | None | 确保结果可以复现的固定随机种子 |
| precrop_iters | 0 | 在central crops训练的步数 |
| precrop_frac | 0.5 | 为central crops拿的图片部分 |
| N_samples | 64 | 每道光线的粗采样数 |
| N_importance | 0 | 每道光线的附加细采样数 |
| perturb | 1. | 0. for no jitter, 1. for jitter |
| use_viewdirs | False | 使用5D而不是3D输入 |
| i_embed | 0 | 0对应默认位置编码,1对应None |
| multires | 10 | 位置编码的最大频率对数(3D位置) |
| multires_views | 4 | 位置编码的最大频率对数(2D方向) |
| raw_noise_std | 0. | std dev of noise added to regularize sigma_a output, 1e0 recommended |
| render_only | False | do not optimize, reload weights and render out render_poses path |
| render_test | False | render the test set instead of render_poses path |
| render_factor | 0 | downsampling factor to speed up rendering, set 4 or 8 for fast preview |
| dataset_type | llff | 三个选项:llff / blender / deepvoxels |
| testskip | 8 | will load 1/N images from test/val sets, useful for large datasets like deepvoxels |
| shape | greek | 四个选项:armchair / cube / greek / vase |
| white_bkgd | False | set to render synthetic data on a white bkgd (always use for dvoxels) |
| half_res | False | load blender synthetic data at 400x400 instead of 800x800 |
| factor | 8 | LLFF图片的降采样因子 |
| no_ndc | False | do not use normalized device coordinates (set for non-forward facing scenes) |
| lindisp | False | sampling linearly in disparity rather than depth |
| spherify | False | set for spherical 360 scenes |
| llffhold | 8 | will take every 1/N images as LLFF test set, paper uses 8 |
| i_print | 100 | 控制台打印频率 |
| i_img | 500 | tesnorboard图片注册频率 |
| i_weights | 1000 | 权重模型保存频率 |
| i_testset | 5000 | 测试集保存频率 |
| i_video | 5000 | 渲染姿态视频保存频率 |
3.2 训练过程
输入数据位于data/nerf_llff_data/fern
输出数据位于logs/fern_test
- 调用run_nerf.py train()函数
- 调用config_parser()函数,获取外部参数args
- 确定random_seed
- 确定数据类型,llff / blender / deepvoxels其中之一。
- 复现使用数据类型为llff,因此调用load_llff.py
load_llff_data()加载数据。
- load_llff_data()传入数据路径(./data/nerf_llff_data/fern)、降采样因子(8)、recenter (True),bd_factor(0.75),spherify(False)
- 根据根据降采样因子处理图片得到新图片(如果不存在)
- 从poses_bounds.npy读取poses和bds,从图片文件夹读取imgs
- 将使用的配置写入args.txt和config.txt
- 使用create_nerf()建立模型
- 如果render_only参数为真,从训练好的模型渲染出结果
- 开启训练
- 输出的视频为螺旋视角移动的视频
3.3 Pose生成
论文作者推荐使用LLFF code[3] 里的脚本imgs2poses.py来生成Pose,然后将数据以llff类型传入模型。于是我先采用一下这个方法。
(以下过程是在ubuntu上编译安装colmap,比较麻烦。在windows上直接安装很简单,下载好之后配上环境变量就行了。)
我一开始使用conda直接安装colmap,但是运行时会报错:
1 | |

这个问题我完全不知道怎么解决,可能3060及其驱动又和程序出现了兼容性问题。
可以从github的相关issue中看到有人提到 SiftGPU is rather old and not optimized with the latest GPU architecture, so it is very inefficient.
但是我的驱动已经是为了在3060上训练模型专门选择过了的,我不想再次更换。
于是我手动编译安装colmap,遇到了以下问题:
- 编译 Ceres Solver这一步会把16G的内存跑满,导致编译失败甚至电脑重启。最好的解决办法是把交换区扩大。我是参考这篇文章把交换区从2G扩大到10G。
- 编译colmap过程中,因为安装了anaconda导致系统库的路径被覆盖掉。进行到这里时,把~/.bashrc里的conda的环境变量注释掉。
- ubuntu21.10自带的gcc (Ubuntu 11.2.0-7ubuntu2) 11.2.0和g++ (Ubuntu 11.2.0-7ubuntu2) 11.2.0版本太高,无法正确编译colmap中的一些模块,因此安装9版本代替11版本(参考)。
手动安装的colmap终于可用了,但我遇到了一个全新的问题。(相同的issue)
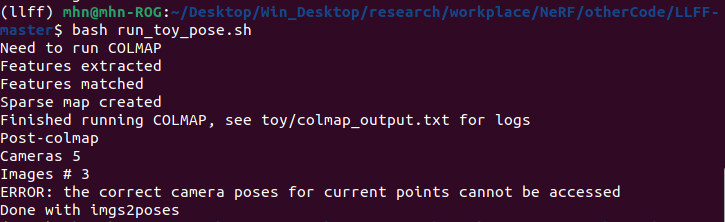
根据我自己的实验,colmap在作者提供的数据集上运行的很完美,说明只是我只是拍的照片不够“好”,不足以让colmap匹配这些图片。(这种情况是,如果我对自己拍摄的照片进行降采样,就会使colmap无法匹配)
我自己用手机拍摄的一个数据集:


实验证明可以用colmap生成相机参数并输入nerf或grf训练。
4.评价标准
4.1 PSNR
Peak Signal to Noise Ratio 峰值信躁比
它是基于对应像素点间误差的图像质量评价。
由于并未考虑到人眼的视觉特性(人眼对空间频率较低的对比差异敏感度较高,人眼对亮度对比差异的敏感度较色度高,人眼对一个区域的感知结果会受到其周围邻近区域的影响等),因而经常出现评价结果与人的主观感觉不一致的情况。
\[ MSE=\frac{1}{H\times W} \sum_{i=1}^{H} \sum_{j=1}^{W}(X(i,j)-Y(i,j))^2 \]
\[ PSNR=10\log_{10}{(\frac{(2^{n}-1)^2}{MSE} )} \]
其中,MSE表示当前图像X和参考图像Y的均方误差(Mean Square Error),H、W分别为图像的高度和宽度;n为每像素的比特数,一般取8,即像素灰阶数为256。
\(PSNR\)的单位是dB,数值越大表示失真越小。
一般来说,\(PSNR\)高于40dB说明图像质量几乎与原图一样好;在30-40dB之间通常表示图像质量的失真损失在可接受范围内;在20-30dB之间说明图像质量比较差;低于20dB说明图像失真严重。
4.2 SSIM
Structural Similarity 结构相似性
它分别从照明度(luminance)、对比度 (contrast) 和结构 (structure)三方面度量图像相似性。 \[ l(X,Y)=\frac{2\mu_{x}\mu_{y}+C_{1}}{\mu_{x}^2+\mu_{y}^2+C_{1}} \]
\[ c(X,Y)=\frac{2\sigma_{x}\sigma_{y}+C_{2}}{\sigma_{x}^2+\sigma_{y}^2+C_{2}} \]
\[ s(X,Y)=\frac{\sigma_{xy}+C_{3}}{\sigma_{x}\sigma_{y}+C_{3}} \]
其中\(\mu_{x}\)、\(\mu_{y}\)分别表示图像X和Y的均值,\(\sigma_{x}\)、\(\sigma_{y}\)分别表示图像X和Y的方差,\(\sigma_{xy}\)表示图像X和Y的协方差。
\(C_{1}\)、\(C_{1}\)、\(C_{3}\)为常数,为了避免分母为0的情况,通常取\(C_{1}=(K_{1}*L)^2\), \(C_{2}=(K_{2}*L)^2\), \(C_{3}=C_{2}/2\),一般地\(K_{1}=0.01\), \(K_{2}=0.03\), \(L=255\)。 \[ SSIM(X,Y)=l(X,Y)c(X,Y)s(X,Y)\sim[0,1] \] \(SSIM\)取值范围\([0,1]\),值越大,表示图像失真越小。
4.3 LPIPS
Learned Perceptual Image Patch Similarity 学习感知图像块相似度
它也称为“感知损失”(perceptual loss),用于度量两张图像之间的差别。[2]
\(LPIPS\)的值越低表示两张图像越相似,反之,则差异越大。
参考文献
复现Extracting
Munkberg J, Hasselgren J, Shen T, et al. Extracting Triangular 3D Models, Materials, and Lighting From Images[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 8280-8290.
装环境的时候使用国内源不要使用-c pytorch
驱动要求:
https://github.com/NVlabs/nvdiffrec/issues/46
安装 CUDA Toolkit 11.7 link
安装 Vulkan SDK (someone mentioned to do this in a linux post) NOTE! Make sure that the Vulkan SDK is in your PATH environment variables: Vulkan SDK Install Instructions
复现GRF
Trevithick A , Yang B . GRF: Learning a General Radiance Field for 3D Scene Representation and Rendering[J]. 2020.
1.运行环境
可以使用与《复现NeRF》完全相同的环境。GRF的代码一部分基于NeRF。
2.实验内容
参考论文中的实验部分。一共四个实验,前三个实验分别验证在不同物体、不同类别、不同场景的泛化能力,最后一个实验验证其在单个场景上的表现也胜过以往。
2.1 不同物体泛化
使用SRN cars and chairs datasets,在cars和chairs这两个数据集上分别训练单独的模型。对每个训练好的模型:
- 喂入一个新物体的2个视角的图片,然后推断其他251个视角的图片。
- 同上,但只喂入一个视角的图片。
2.2 不同类别泛化
使用DISN MultiShapenet dataset,在 {chair,bench,car,airplane,table,speaker} 6个类别的数据集上训练,在{cabinet,display,lamp,phone,rifle,sofa,watercraft} 7个新类别上验证。对于训练好模型:
- 喂入属于新类别的一个新物体的2个视角的图片,然后推断全部36个视角的图片。
- 同上,喂入6个视角的图片。
2.3 不同场景泛化
使用NeRF dataset,对于其中的8个合成场景,随机选取4个场景进行训练。对于训练好的模型:
- 将它直接在其它4个新场景上进行验证。
- 将它分别在其他4个新场景上进行微调(分别训练100,1k,10k次),这样就得到3*4=12个新模型。使用NeRF分别在这4个新场景上训练(分别训练100,1k,10k次),然后与之对比。
2.4 单个场景表现
使用NeRF dataset,在单个场景上进行训练,与NeRF对比。
3. 实际运行
3.1 不同物体泛化
因为chairs数据集太大了,这里只使用cars数据集。将cars_test.zip,cars_train.zip,cars_train_test.zip,cars_train_val.zip,cars_val.zip五个压缩包下载下来,解压并把文件夹名字去掉“cars_”前缀。
使用python run.py --config config_shapenet_cars.txt运行程序。这里使用和作者一摸一样的配置。
注意事项:
如果在windows下运行,config文件中数据路径写的windows路径,记得将load_shapenet_rewrite_lowmem.py里的load_shapenet_data函数中对文件路径操作时用的分隔符从'/'换成'//'。
数据集中有部分数据不合法,不满足load_shapenet_rewrite_lowmem.py里的read_scene函数中的
1
assert len(rgb_files) == len(pose_files), scene_path因此加上if判定忽视掉不合法数据使程序正常运行。
run.py中的render_rays函数最后的检查语句会报错,因此将其注释掉:
1
tf.debugging.check_numerics(ret[k], 'output {}'.format(k))这很奇怪,因为我采用与作者一摸一样的配置。
备注:GRF的render_rays函数与NeRF中的render_rays函数基本相同。NeRF中这个检查语句在我训练forward-facing场景时不会报错,训练360度场景时则会报错,但训练结果都是正常的。
第一次训练后发现没有tensorboard输出。后续有空给代码加上。
训练情况:
使用24G的3090,显存基本占满。根据作者的说法他将32G的V100占满了。
GRF开始的训练是正常的,过了一段时间之后acm_loss全部变成nan。
根据作者在Github Issue中的说法,训练400k次应该是足够的,因此我训练了30个小时完成400次。
复现iBRDF
Chen Z, Nobuhara S, Nishino K. Invertible neural BRDF for object inverse rendering[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021.
1 环境
操作系统
Distributor ID: Ubuntu
Description: Ubuntu 22.04.1 LTS
Release: 22.04
Codename: jammy
Docker
Client: Docker Engine - Community
Version: 20.10.17
API version: 1.41
Go version: go1.17.11
Git commit: 100c701
Built: Mon Jun 6 23:02:46 2022
OS/Arch: linux/amd64
Context: default
Experimental: true
Server: Docker Engine - Community
Engine:
Version: 20.10.17
API version: 1.41 (minimum version 1.12)
Go version: go1.17.11
Git commit: a89b842
Built: Mon Jun 6 23:00:51 2022
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.6.7
GitCommit: 0197261a30bf81f1ee8e6a4dd2dea0ef95d67ccb
runc:
Version: 1.1.3
GitCommit: v1.1.3-0-g6724737
docker-init:
Version: 0.19.0
GitCommit: de40ad0
依赖:
- A C++ 17-compatible compiler
- CUDA 10.2
- CMake
- LibTorch 1.6.0
- OptiX 7.0.0
- TinyEXR (bundled)
2 实验过程
使用docker/下的脚本构建容器ranix。
如果运行容器时报错找不到设备驱动:
1 | |
可以按照教程安装NVIDIA
Container
Runtime,使用systemctl restart docker重启服务,解决这个问题。
下载MERL BRDF,将二进制文件放到./datasets/merl目录下。挂vpn无法一次性下载全部,只能逐部下载。

下载代码到iBRDF-main。
下载指定版本libtorch和optix到./iBRDF-main/third_party/下。
运行容器ranix,将iBRDF-main和datasets复制到ranix:/root/workspace中。
进入iBRDF-main,使用cmake编译项目。
1 | |
建立文件夹../datasets/merl_processed,进入iBRDF-main运行脚本转换BRDF数据格式适合训练:
1 | |
训练iBRDF
1 | |
报错:
1 | |
可能是libtorch版本并不能用1.6.0
复现ingp
Müller T, Evans A, Schied C, et al. Instant neural graphics primitives with a multiresolution hash encoding[J]. arXiv preprint arXiv:2201.05989, 2022.
1.实验环境
RTX3090
CUDA 11.4
VS2019
编译过程中可能会遇到很多问题,具体参考github里的issue
远程控制主机,若主机不连接显示器,opengl渲染会出现白屏。
经过一次更新之后(https://github.com/NVlabs/instant-ngp/issues/36#issuecomment-1036198048),ingp对显存的需求量大大降低。
2.使用即时神经图形基元训练NeRF模型的技巧
我们的NeRF实现期望初始相机参数以 transforms. json的格式提供,和原始的NeRF代码库兼容。我们提供了一个方便的脚本,scripts/colmap2nerf.py,它可以用来处理视频文件或图像序列,使用开源的COLMAP( structure from motion,SFM软件)来提取必要的摄像机数据。
训练过程可能对数据集非常挑剔。例如,重要的是数据集要有良好的覆盖率,不要包含错误标记的相机数据,不要包含模糊的帧(运动模糊和离焦模糊都是有问题的)。这篇问题试图给出一些技巧。一个很好的经验法则是,如果你的NeRF模型在20秒左右没有收敛,那么在长时间的训练之后,它就不太可能变得更好。因此,我们建议调整数据,以在培训的早期阶段获得明确的结果。对于大型的真实世界场景,可以通过最多几分钟的训练获得一点额外的清晰度。几乎所有的收敛都发生在最初的几秒钟。
数据集最常见的问题是相机位置的不正确比例或偏移(更多细节见下面)。第二个最常见的问题是图像太少,或者图像的相机参数不准确(例如,如果COLMAP失败)。在这种情况下,您可能需要获取更多的图像,或者调整计算相机位置的过程。这超出了instant-npg实现的范围。
2.1 已有数据集
默认情况下,instant-ngp的NeRF实现只将射线通过从[0,0,0]到[1,1,1]的单元边界框。默认情况下,数据加载器在输入JSON文件中接受摄像机转换,并将位置缩放0.33,偏移量[0.5,0.5,0.5],以便将输入数据的原点映射到立方体的中心。缩放因子的选择是为了适应原始NeRF论文中的合成数据集,以及我们的脚本/colmap2nerf.py脚本的输出。
通过在UI的 "Debug visualization"中选择 "Debug visualization"和 "Visualize unit cube" 来检查你的摄像机与这个包围框的对齐方式是值得的,如下图所示:

对于单位立方体外有可见背景的自然场景,需要在 transforms.json文件中把参数aabb_scale设置为2次幂(即1、2、4、8或16),在最外层的作用域(与现有的camera_angle_x参数相同的嵌套)。data/nerf/fox/transforms.json是个例子。
效果如下图所示:

摄像机仍然以单位立方体中的“感兴趣的对象”为中心;然而,aabb_scale参数,在这里设置为16,导致NeRF实现跟踪射线到一个更大的边界框(边长16),包含背景元素,中心在[0.5,0.5,0.5]。
2.2 扩展现有的数据集
如果你有一个transform.json格式的数据集,它应该以原点为中心,并和原始的NeRF synthetic datasets规模近似。当你把它加载到NGP中时,如果你发现它没有收敛,首先要检查的是相机相对于立方体单元的位置,使用上面描述的调试功能。如果数据集不在单元立方体中占主导地位,则值得将其移到那里。你可以通过调整转换本身来做到这一点,或者你可以在json的外部范围中添加全局参数。
您可以设置以下任何参数,其中列出的值为默认值。
1 | |
实现细节和附加选项参见nerf_loader. cu。
2.3 准备新的NeRF数据集
确保您已经安装了COLMAP,并且它在您的PATH中可用。如果您使用一个视频文件作为输入,也要确保安装FFmpeg,并确保它在您的PATH中可用。要检查这种情况,从一个终端窗口,您应该能够运行colmap和ffmpeg -?并从中看到一些帮助文本。
如果您正在从视频文件中进行训练,请在包含视频的文件夹中运行scripts/colmap2nerf.py脚本,并使用以下推荐参数:
1 | |
上面假设输入一个视频文件,然后按指定的帧率(2)提取帧。建议选择帧率在50-150左右的图像。对于一分钟的视频,——video_fps 2是理想的。
如果从图像中进行训练,将它们放在名为images的子文件夹中,然后使用合适的选项,如下面的选项:
1 | |
脚本将根据需要运行FFmpeg和/或COLMAP,然后执行转换到所需transforms.json格式的步骤,该步骤将写入当前目录。
默认情况下,脚本使用“顺序匹配器”调用colmap,它适用于从平滑变化的摄像机路径中拍摄的图像,比如视频。如果图像没有特定的顺序,则穷举匹配器更合适,如上面的图像示例所示。要了解更多选项,可以使用——help运行脚本。有关COLMAP更高级的使用或具有挑战性的场景,请参阅COLMAP文档;您可能需要修改脚本/colmap2nerf.py脚本本身。
aabb_scale参数是最重要的instant-ngp特定参数。它指定场景的范围,默认值为1;也就是说,场景被缩放,使得摄像机位置距离原点的平均距离为1个单位。对于小型的合成场景,如原始NeRF数据集,默认的aabb_scale为1是理想的,可以获得最快的训练。NeRF模型假设训练图像可以完全被包含在这个边界框中的场景所解释。然而,在自然场景中,背景超出了这个边界框,NeRF模型会在框的边界出现“飞蚊”。通过将aabb_scale设置为2的更大的幂(最高为16),NeRF模型将射线扩展到一个更大的边界框。注意,这可能会轻微影响训练速度。如果有疑问,对于自然场景,首先将aabb_scale设置为16,然后如果可能的话将其缩小。值可以在 transforms. json输出文件直接编辑,无需重新运行scripts/colmap2nerf.py脚本。
假设成功,你现在可以训练你的NeRF模型如下,从instant-ngp文件夹开始:
1 | |
2.4 NeRF训练数据的技巧
NeRF模型在50-150张图像之间训练得最好,这些图像需要表现出最小的场景移动,运动模糊或其他人为模糊。COLMAP能够从图像中提取准确的相机参数,从而保证了重建的质量。有关如何验证这一点的信息,请参阅前面的部分。
colmap2nerf.py脚本假设所有训练图像都大约指向一个共享的兴趣点,它将这个点放置在原点。这个点是通过所有对训练图像的中心像素对光线之间最近的接近点取加权平均来找到的。在实践中,这意味着当训练图像指向感兴趣的对象时,脚本工作得最好,尽管它们不需要完成该对象的360度全景。如果将aabb_scale设置为大于1的数值,则感兴趣对象后面的任何可见背景仍然会被重建,如上所述。
复现Mip-NeRF
Barron J T, Mildenhall B, Tancik M, et al. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields[J]. arXiv preprint arXiv:2103.13415, 2021.
1. 运行环境
1.1 ubuntu
系统版本:21.10
显卡:NVIDIA GeForce RTX 3060 Laptop GPU
python环境:按照作者github的原环境安装即可,记得使用国内源加速 -i https://pypi.doubanio.com/simple。建议手动安装,直接pip install -r requirements.txt会下载很多多余的包,并且手动安装可以选择适配自己环境的。我安装的是tensorflow-gpu==2.5.0。
tensorflow 2.x不再区分是否gpu,当检测到gpu并安装cuda后,自动调用gpu。
2.实验内容
作者使用NeRF官方数据集。使用以下命令从nerf_synthetic生成multiscale数据集:
1 | |
batch_size默认4096 ,我的显存6G,将batch_size调小为512。
直接运行,会报错:
1 | |
这个怀疑是因为显存分配有问题。
并且,偶尔进程会被系统kill,怀疑是因为16G内存不够用。
复现NeuTex
Xiang F , Xu Z , Haan M , et al. NeuTex: Neural Texture Mapping for Volumetric Neural Rendering[J]. 2021.
1. 运行环境
1.1 ubuntu
系统版本:21.10
显卡:NVIDIA GeForce RTX 3060 Laptop GPU
python环境:pytorch gpu版本加上trimesh、hdf5、h5py
备注:直接pip install torch的话会装成cpu版本,特别是添加了其他channel的情况下。另外,系统中安装了cuda就不需要按照官网的安装命令在conda中安装cudatoolkit, 会发生冲突。我的显卡环境是cuda11.2+cudnn8.1,我的pytorch安装命令如下。
1 | |
1.2 windows
系统版本:windows10
显卡:NVIDIA GeForce RTX 3060 Laptop GPU
python环境:和ubuntu一摸一样
将原工程里的dtu.sh重写为dtu.bat即可在windows下运行。在Anaconda prompt中在配好的环境下执行 ..bat 114即可。
2.实验内容
2.1 运行作者提供的DTU scene
首先,程序根据入参的dataset_name(“dtu”)加载实现写好的dtu_dataset.py类,用这个类从入参的data_root("DTU/scan%1%/trainData",%1%为入参114)下加载训练数据。它加载的就是存在hdf5里的图片数据和一些相机参数以及点云,还有用来分离图片背景的mask。
运行没有问题。
要使用自己的输入数据的话,需要根据作者的要求写一个自己的数据加载类,加载指定需要的数据即可(而类中的加载方式怎么写都行,所以源数据格式不重要)。
复现NLT
Zhang X , Fanello S , Tsai Y T , et al. Neural Light Transport for Relighting and View Synthesis[J]. 2020.
1.运行环境
原工程在ubuntu下测试,并且作者自己写的第三方库不兼容windows,因此其不能在windows上运行。
为了使其在3060、cuda11.2.0、cudnn8.1.1下运行,将原conda环境更改如下:
1 | |
2.实验内容
2.1 使用作者的数据复现
在作者的项目主页下载dragon_specular.zip,dragon_sss.zip。
可以在环境变量中添加作者自己的第三方库,也可以在pycharm的configurations中添加运行时的环境变量,注意ubuntu中的环境变量用:隔开。
原代码是在ubuntu上运行的,因此配置文件里在文件名中使用:,而这在windows下是不允许的,可以将其修改为$。
但是作者的自己写的第三方库并没有兼容windows,运行会报错:
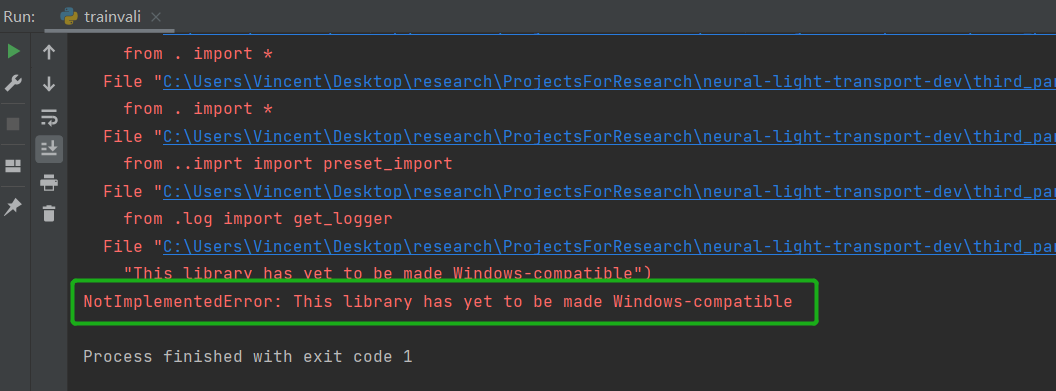
非常坑的一点就是中断之后重新运行,不会加载原来保存的checkpoint而是直接覆盖输出目录重新从0开始训练,记得把配置文件里的overwrite改为False。
作者配置文件里的bs对应batch_size,值是4。直接跑的话可能会因为显存不够进程挂掉(有时候不会),改为2进行训练。大概需要30个小时完成训练(3060,6G显存)。
dragon_specular.zip训练结果:

dragon_sss.zip训练所需的神经网络学习率是前者的1/4,且深度是前者的4倍,可能会慢很多。并且将其batch size减半依然超出6G显存,暂时没有训练。
复现plenoxel
Fridovich-Keil S, Yu A, Tancik M, et al. Plenoxels: Radiance Fields Without Neural Networks[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 5501-5510.
1.运行环境
注释掉原environment.yml中的pytorch、torchvision、cudatoolkit。直接pip install torch的话会装成cpu版本。应使用如下命令安装:
1 | |
使用以下命令安装库(svox2):
1 | |
2.运行
下载作者训练好的模型,直接进行评估。
1 | |
在RTX3060上,渲染一个40秒、30帧的视频需要20分钟左右的时间和4-5G显存。