《DirectX 12 3D 游戏开发实战》笔记
Introduction to 3D Game Programming with DirectX 12
Frank D. Luna 著
王陈 译

摘录整理。
未完成
注意
对书中第一个实例进行编译时可能遇到错误,可以参考这篇文章。将项目属性中的【语言】的【符合模式】设置为否(或者默认),检查就不严格了。
前言
DirectX SDK在MSDN上的最新文档为《Direct3D 12 Programming Guide》,即《Direct3D 12编程指南》。
书中创建演示项目需要注意的地方(书中使用VS2015):
以VS2022为例,创建新项目,C++ -> Windows桌面向导 -> 选择桌面应用程序,勾选空项目
通过在源代码文件Common/d3dApp.h中使用#pragma预处理指令来链接所需的库文件,如:
1 | |
对于创建演示程序而言,该预处理指令使我们免于打开项目属性页面并在连接器配置项下指定附加依赖库。
可能需要修改CompileShader里shader文件的相对路径。比如如果没有勾选“将解决方案和目录放在同一目录中”,原相对路劲需要加上..//,因为多了一层。
本书使用方法3编译着色器文件。
尤其是到了Direct3D 12,更像Mantle等API那样实现了前所未有的更底层的硬件抽象,削减驱动层的工作,转交给开发者负责,从而令图形的处理流程更加“智能”,使用起来犹如贴地飞行的“快感”。
DirectX包罗系列与多媒体以及游戏开发有关的API,因此Direct3D只是DirectX的一个子集。详细信息请见《DirectX Graphics and Graming》(ee663274)。本书则侧重Direct3D的讲解。
建议先把本书附录ABC看完。
第一部分 必备的数学知识
第1章 向量代数
向量(vector)是一种兼具大小(也称为模,magnitude)和方向的量。具有这两种属性的量皆称为向量值物理量(vector-valued quantity)。
Direct3D采用的是左手坐标系(left-handed coordinate system)。如果我们伸出左手,并拢手指,假设它们指向的是x轴的正方向,再弯曲四指指向y轴的正方向,则最后伸直拇指的方向大约就是z轴的正方向。
把一个向量的长度变为单位长度称为向量的规范化(normalizing)处理。
对于具有n个向量的一般集合而言,为了将其正交化为规范正交集,我们就要使用格拉姆—施密特正交化(Gram-Schmidt Orthogonalization)方法进行处理。
只有3D向量的叉积有定义(不存在2D向量叉积)。
对于Windows 8及其以上版本来讲,DirectXMath(其前身为XNA Math数学库,DirectXMath正是基于此而成)是一款为Direct3D应用程序量身打造的3D数学库,而它也自此成为了Windows SDK的一部分。该数学库采用了SIMD流指令扩展2(Streaming SIMD Extensions 2,SSE2)指令集。借助128位宽的单指令多数据(Single Instruction Multiple Data,SIMD)寄存器,利用一条SIMD指令即可同时对4个32位浮点数或整数进行运算。
对于希望了解如何开发一个优秀的SIMD向量库,乃至希望深入理解DirectXMath库设计原理的读者,我们在这里推荐一篇文章《Designing Fast Cross-Platform SIMD Vector Libraries(设计快速的跨平台SIMD向量库)》。
DirectXMath库对应头文件#include <DirectXMath.h>和#include <DirectXPackedVector.h>。除此之外并不需要其他的库文件,因为所有的代码都以内联的方式实现在头文件里。DirectXMath.h文件中的代码都存在于DirectX命名空间之中,而DirectXPackedVector.h文件中的代码则都位于DirectX::PackedVector命名空间以内。
在DirectXMath库中,核心的向量类型是XMVECTOR,它将被映射到SIMD硬件寄存器。通过SIMD指令的配合,利用这种具有128位的类型能一次性处理4个32位的浮点数。在开启SSE2后,此类型在x86和x64平台的定义是:
1 | |
这里的__m128是一种特殊的SIMD类型(定义见xmmintrin.h)。在计算向量的过程中,必须通过此类型才可充分地利用SIMD技术。正如前文所述,我们将通过SIMD技术来处理2D和3D向量运算,而计算过程中用不到的向量分量则将它置零并忽略。
XMVECTOR类型的数据需要按16字节对齐,对于局部变量和全局变量而言都是自动实现的。至于类中的数据成员,建议分别使用XMFLOAT2(2D向量)、XMFLOAT3(3D向量)和XMFLOAT4(4D向量)类型来加以代替。
XMVECTOR使用方法:
- 局部变量或全局变量用XMVECTOR类型。
- 对于类中的数据成员,使用XMFLOAT2、XMFLOAT3和XMFLOAT4类型。
- 在运算之前,通过加载函数将XMFLOATn类型转换为XMVECTOR类型。
- 用XMVECTOR实例来进行运算。
- 通过存储函数将XMVECTOR类型转换为XMFLOATn类型。
1 | |
1 | |
为了使代码更具通用性,不受具体平台、编译器的影响,我们将利用FXMVECTOR、GXMVECTOR、HXMVECTOR和CXMVECTOR类型来传递XMVECTOR类型的参数。基于特定的平台和编译器,它们会被自动地定义为适当的类型。
一定要把调用约定注解XM_CALLCONV加在函数名之前,它会根据编译器的版本确定出对应的调用约定属性。
传递XMVECTOR参数的规则如下:
- 前3个XMVECTOR参数应当用类型FXMVECTOR;
- 第4个XMVECTOR参数应当用类型GXMVECTOR;
- 第5、6个XMVECTOR参数应当用类型HXMVECTOR;
- 其余的XMVECTOR参数应当用类型CXMVECTOR。
传递XMVECTOR参数的规则仅适用于“输入”参数。“输出”的XMVECTOR参数(即XMVECTOR&或XMVECTOR*)则不会占用SSE/SSE2寄存器,所以它们的处理方式与非XMVECTOR类型的参数一致。
在编写构造函数时,前3个XMVECTOR参数用FXMVECTOR类型,其余XMVECTOR参数则用CXMVECTOR类型。另外,对于构造函数不要使用XM_CALLCONV注解。
XMVECTOR类型的常量实例应当用XMVECTORF32类型来表示。
即使在数学上计算的结果是标量(如点积),库函数所返回的类型依旧是XMVECTOR,而得到的标量结果则被复制到XMVECTOR中的各个分量之中。这样做的原因之一是:将标量和SIMD向量的混合运算次数降到最低,使用户除了自定义的计算之外全程都使用SIMD技术,以提升计算效率。
第2章 矩阵代数
从几何的角度来解释行列式,行列式反映了在线性变换下,(n维多面体)体积变化的相关信息。另外,行列式也应用于解线性方程组的克莱姆法则(Cramer’s Rule,亦称克莱默法则)。此书中学习行列式的主要目的是:利用它推导出求逆矩阵的公式。此外,行列式还可以用于证明:方阵A是可逆的,当且仅当detA不为0。
在3D图形学中,主要使用4X4矩阵。
存在逆矩阵的方阵称为可逆矩阵(invertible matrix),不存在逆矩阵的方阵称作奇异矩阵(singular matrix)。 \[ A^{-1}=\frac{A^*}{detA} \] 对于规模较小的矩阵(4x4及其以下规模的矩阵)来说,运用伴随矩阵的方法将得到不错的计算效率。但针对规模更大的矩阵而言,就要使用诸如高斯消元法(Gaussian elimination,也作高斯消去法)等其他手段。由于我们关注于3D计算机图形学中所涉及的具有特殊形式的矩阵,因此也就提前确定出了它们的求逆矩阵公式。
DirectXMath以定义在DirectXMath.h头文件中的XMMATRIX类来表示4x4矩阵。
就像通过XMFLOAT2 (2D),XMFLOAT3 (3D)和XMFLOAT4 (4D)来存储类中不同维度的向量一样,DirectXMath文档也建议我们用XMFLOAT4X4来存储类中的矩阵类型数据成员。
1 | |
加载与存储:
1 | |
在声明具有XMMATRIX参数的函数时,除了要注意1个XMMATRIX应计作4个XMVECTOR参数这一点之外,其他的规则与传入XMVECTOR类型的参数时相一致。假设传入函数的FXMVECTOR参数不超过两个,则第一个XMMATRIX参数应当为FXMMATRIX类型,其余的XMMATRIX参数均应为CXMMATRIX类型。
在32位Windows操作系统上的__fastcall调用约定中,XMMATRIX类型的参数是不能传至SSE/SSE2寄存器的,因为这些寄存器此时只支持3个XMVECTOR参数传入。而XMMATRIX参数却是由4个XMVECTOR构成,所以矩阵类型的数据只能通过堆栈来加以引用。
DirectXMath建议用户总是在构造函数中采用CXMMATRIX类型来获取XMMATRIX参数,而且对于构造函数也不要使用XM_CALLCONV约定注解。
第3章 变换
旋转矩阵有个有趣的性质:每个行向量都为单位长度且两两正交。也就是说,这些行向量都是规范正交的(orthonormal,即互相正交且具有单位长度)。若一个矩阵的行向量都是规范正交的,则称此矩阵为正交矩阵(orthogonal matrix)。正交矩阵有个引人注目的性质,即它的逆矩阵与转置矩阵是相等的。
仿射变换(affine transformation)是由一个线性变换与一个平移变换组合而成的。
我们通过4x4矩阵来表示变换,并利用1x4齐次坐标来描述点和向量。在采用齐次坐标表示法时,我们将坐标扩充为四元组,其中,第四个坐标w的取值将根据被描述对象是点还是向量而定。具体来讲:
1.(x,y,z,0)表示向量
2.(x,y,z,1)表示点
设w=1能使点被正确地平移,设w=0则可以防止向量坐标受到平移操作的影响。
我们能够将一个改变几何体的复合变换(缩放、旋转和平移),解释为一种对应的坐标变换。由于我们以后通常要将世界空间的坐标变换矩阵定义为缩放、旋转和平移操作组成的复合变换,所以了解这一点是很重要的。
由于矩阵的乘法运算满足结合律,因此我们就能够将若干种变换矩阵合而为一。此矩阵给予物体的变换效果,与合成它的多个单一矩阵对物体按次序进行变换的净效果相同。
第二部分 Direct3D基础
第4章 Direct3D的初始化
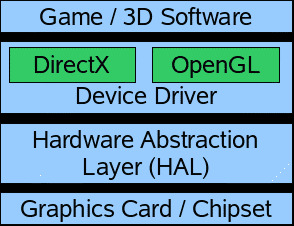
GPU的生产厂商如NVIDIA、Intel和AMD等公司就必须与Direct3D团队一同合作,为用户提供与Direct3D设备相兼容的驱动。
除了添加一些新的渲染特性以外,Direct3D 12经重新设计已焕然一新,较之上一个版本的主要改变在于其性能优化方面在大大减少了CPU开销的同时,又改进了对多线程的支持。为了达到这些性能目标,Direct3D 12的API较Direct3D 11更偏于底层。另外,API抽象程度的降低使它更趋于具体化,与现代GPU的构架也更为契合,因此也就促使开发者要付出比昔日更多的努力。当然,使用这种更复杂的API所得到的回报是:性能的提升。
组件对象模型(Component Object Model,COM)是一种令DirectX不受编程语言束缚,并且使之向后兼容的技术。
我们通常将COM对象视为一种接口,但考虑当前编程的目的,遂将它当作一个C++类来使用。用C++语言编写DirectX程序时,COM帮我们隐藏了大量底层细节。我们只需知道:要获取指向某COM接口的指针,需借助特定函数或另一COM接口的方法——而不是用C++语言中的关键字new去创建一个COM接口。另外,COM对象会统计其引用次数;因此,在使用完某接口时,我们便应调用它的Release方法(COM接口的所有功能都是从IUnknown这个COM接口继承而来的,包括Release方法在内),而不是用delete来删除——当COM对象的引用计数为0时,它将自行释放自己所占用的内存。
为了辅助用户管理COM对象的生命周期,Windows运行时库(Windows Runtime Library,WRL)专门为此提供了Microsoft::WRL::ComPtr类(#include <wrl.h>),我们可以把它当作是COM对象的智能指针。当一个ComPtr实例超出作用域范围时,它便会自动调用相应COM对象的Release方法,继而省掉了我们手动调用的麻烦。
本书中常用的3个ComPtr方法如下。
Get:返回一个指向此底层COM接口的指针。此方法常用于把原始的COM接口指针作为参数传递给函数。
1
2
3
4ComPtr<ID3D12RootSignature> mRootSignature;
...
// SetGraphicsRootSignature需要获取ID3D12RootSignature*类型的参数
mCommandList->SetGraphicsRootSignature(mRootSignature.Get());GetAddressOf:返回指向此底层COM接口指针的地址。凭此方法即可利用函数参数返回COM接口的指针。
1
2
3ComPtr<ID3D12CommandAllocator> mDirectCmdListAlloc;
...
ThrowIfFailed(md3dDevice->CreateCommandAllocator(D3D12_COMMAND_LIST_TYPE_DIRECT,mDirectCmdListAlloc.GetAddressOf()));Reset:将此ComPtr实例设置为nullptr释放与之相关的所有引用(同时减少其底层COM接口的引用计数)。此方法的功能与将ComPtr目标实例赋值为nullptr的效果相同。
COM接口都以大写字母“I”作为开头。例如,表示命令列表的COM接口为ID3D12GraphicsCommandList。
2D纹理(2D texture)是一种由数据元素构成的矩阵(可将此“矩阵”看作2D数组)。
并不是任意类型的数据元素都能用于组成纹理,它只能存储DXGI_FORMAT枚举类型中描述的特定格式的数据元素。下面是一些相关的格式示例:
DXGI_FORMAT_R32G32B32_FLOAT:每个元素由3个32位浮点数分量构成。
DXGI_FORMAT_R16G16B16A16_UNORM:每个元素由4个16位分量构成,每个分量都被映射到 [0, 1] 区间。
DXGI_FORMAT_R32G32_UINT:每个元素由2个32位无符号整数分量构成。
DXGI_FORMAT_R8G8B8A8_UNORM:每个元素由4个8位无符号分量构成,每个分量都被映射到 [0, 1] 区间。
DXGI_FORMAT_R8G8B8A8_SNORM:每个元素由4个8位有符号分量构成,每个分量都被映射到 [−1, 1] 区间。
DXGI_FORMAT_R8G8B8A8_SINT:每个元素由4个8位有符号整数分量构成,每个分量都被映射到 [−128, 127] 区间。
DXGI_FORMAT_R8G8B8A8_UINT:每个元素由4个8位无符号整数分量构成,每个分量都被映射到 [0, 255] 区间。
为了避免动画中出现画面闪烁的现象,最好将动画帧完整地绘制在一种称为后台缓冲区的离屏(off-screen,即不可直接呈现在显示设备上之意)纹理内。前台缓冲区存储的是当前显示在屏幕上的图像数据,而动画的下一帧则被绘制在后台缓冲区里。当后台缓冲区中的动画帧绘制完成之后,两种缓冲区的角色互换:后台缓冲区变为前台缓冲区呈现新一帧的画面,而前台缓冲区则为了展示动画的下一帧转为后台缓冲区,等待填充数据。前后台缓冲的这种互换操作称为呈现(presenting,亦有译作提交、显示等)。呈现是一种高效的操作,只需交换指向当前前台缓冲区和后台缓冲区的两个指针即可实现。
前台缓冲区和后台缓冲区构成了交换链(swap chain),在Direct3D中用IDXGISwapChain接口来表示。
即便纹理中存储的不是颜色信息,大家有时也称纹理的元素为像素(如“法线图中的像素”)。
深度缓冲区(depth buffer)这种纹理资源存储的并非图像数据,而是特定像素的深度信息。深度值的范围为0.0~1.0。0.0代表观察者在视锥体(view frustum,亦有译作视域体、视景体、视截体或视体等,意即观察者能看到的空间范围,形如从四棱锥中截取的四棱台,常称该形为平截头体(frustum))中能看到离自己最近的物体,1.0则代表观察者在视锥体中能看到离自己最远的物体。深度缓冲区中的元素与后台缓冲区内的像素呈一一对应关系(即后台缓冲区中第i行第j列的元素对应于深度缓冲区内第i行第j列的元素)。
若使用了深度缓冲,则物体的绘制顺序也就变得无关紧要了。
深度缓冲可用的格式包括以下几种:
DXGI_FORMAT_D32_FLOAT_S8X24_UINT:该格式共占用64位,取其中的32位指定一个浮点型深度缓冲区,另有8位(无符号整数)分配给模板缓冲区(stencil buffer),并将该元素映射到[0, 255]区间,剩下的24位仅用于填充对齐(padding)不作他用。
DXGI_FORMAT_D32_FLOAT:指定一个32位浮点型深度缓冲区。
DXGI_FORMAT_D24_UNORM_S8_UINT:指定一个无符号24位深度缓冲区,并将该元素映射到[0, 1]区间。另有8位(无符号整型)分配给模板缓冲区,将此元素映射到[0, 255]区间。
DXGI_FORMAT_D16_UNORM:指定一个无符号16位深度缓冲区,把该元素映射到[0, 1]区间。
深度缓冲区将总是与模板缓冲区如影随形,深度缓冲区叫作深度/模板缓冲区更为得体。
在发出绘制命令之前,我们需要将与本次绘制调用(draw call)相关的资源绑定(bind或称链接,link)到渲染流水线上。部分资源可能在每次绘制调用时都会有所变化,所以我们也就要每次按需更新绑定。但是,GPU资源并非直接与渲染流水线相绑定,而是要通过一种名为描述符(descriptor)的对象来对它间接引用,我们可以把描述符视为一种对送往GPU的资源进行描述的轻量级结构。从本质上来讲,它实际上即为一个中间层;若指定了资源描述符,GPU将既能获得实际的资源数据,也能了解到资源的必要信息。
为什么我们要额外使用描述符这个中间层呢?
究其原因,GPU资源实质都是一些普通的内存块。由于资源的这种通用性,它们便能被设置到渲染流水线的不同阶段供其使用。一个常见的例子是先把纹理用作渲染目标(即Direct3D的绘制到纹理技术),随后再将该纹理作为一个着色器资源(即此纹理会经采样而用作着色器的输入数据)。不管是充当渲染目标、深度/模板缓冲区还是着色器资源等角色,仅靠资源本身是无法体现出来的。而且,我们有时也许只希望将资源中的部分数据绑定至渲染流水线,但如何从整个资源中将它们选取出来呢?再者,创建一个资源可能用的是无类型格式,这样的话,GPU甚至不会知道这个资源的具体格式。
解决上述问题就是引入描述符的原因。除了指定资源数据,描述符还会为GPU解释资源:它们会告知Direct3D某个资源将如何使用(即此资源将被绑定在流水线的哪个阶段上),而且我们可借助描述符来指定欲绑定资源中的局部数据。这就是说,如果某个资源在创建的时候采用了无类型格式,那么我们就必须在为它创建描述符时指明其具体类型。
视图(view)与描述符(descriptor)是同义词。“视图”虽是Direct3D先前版本里的常用术语,但它仍然沿用在Direct3D 12的部分API中。在本书里,两者交替使用,例如,“常量缓冲区视图(constant buffer view)”与“常量缓冲区描述符(constant buffer descriptor)”表达的是同一事物。
每个描述符都有一种具体类型,此类型指明了资源的具体作用。本书常用的描述符如下:
- CBV/SRV/UAV描述符分别表示的是常量缓冲区视图(constant bufferview)、着色器资源视图(shader resource view)和无序访问视图(unorderedaccess view)这3种资源。
- 采样器(sampler,亦有译为取样器)描述符表示的是采样器资源(用于纹理贴图)。
- RTV描述符表示的是渲染目标视图资源(render target view)。
- DSV描述符表示的是深度/模板视图资源(depth/stencil view)。
描述符堆(descriptor heap)中存有一系列描述符(可将其看作是描述符数组),本质上是存放用户程序中某种特定类型描述符的一块内存。我们需要为每一种类型的描述符都创建出单独的描述符堆。另外,也可以为同一种描述符类型创建出多个描述符堆。
能用多个描述符来引用同一个资源。例如,可以通过多个描述符来引用同一个资源中不同的局部数据。而且,前文曾提到过,一种资源可以绑定到渲染流水线的不同阶段。因此,对于每个阶段都需要设置独立的描述符。例如,当一个纹理需要被用作渲染目标与着色器资源时,我们就要为它分别创建两个描述符:一个RTV描述符和一个SRV描述符。类似地,如果以无类型格式创建了一个资源,又希望该纹理中的元素可以根据需求当作浮点值或整数值来使用,那么就需要为它分别创建两个描述符:一个指定为浮点格式,另一个指定为整数格式。
创建描述符的最佳时机为初始化期间。由于在此过程中需要执行一些类型的检测和验证工作,所以最好不要在运行时(runtime)才创建描述符。
超级采样和多重采样的关键区别是显而易见的。对于超级采样来说,图像颜色要根据每一个子像素来计算,因此每个子像素都可能各具不同的颜色。而以多重采样的方式来求取图像颜色时,每个像素只需计算一次,最后,再将得到的颜色数据复制到多边形覆盖的所有可见子像素之中。
1 | |
功能级别为不同级别所支持的功能进行了严格的界定(每个功能级别所支持的特定功能可参见SDK文档)。例如,一款支持功能级别11的GPU,除了个别特例之外(像类似于多重采样数量这样的信息仍然需要查询,因为Direct3D规范允许这些Direct3D 11硬件在此方面有各自不同的实现),必须支持完整的Direct3D 11功能集。功能集使程序员的开发工作更加便捷——只要了解所支持的功能集,就能知道有哪些Direct3D功能可供使用。
DirectX图形基础结构(DirectX Graphics Infrastructure,DXGI,也有译作DirectX图形基础设施)是一种与Direct3D配合使用的API。设计DXGI的基本理念是使多种图形API中所共有的底层任务能借助一组通用API来进行处理。例如,为了保证动画的流畅性,2D渲染与3D渲染两组API都要用到交换链和页面翻转功能,这里所用的交换链接口IDXGISwapChain实际上就属于DXGIAPI。DXGI还用于处理一些其他常用的图形功能,如切换全屏模式(full-screenmode。另一种是窗口模式,windowed mode),枚举显示适配器、显示设备及其支持的显示模式(分辨率、刷新率等)等这类图形系统信息。除此之外,它还定义了Direct3D支持的各种表面格式信息(DXGI_FORMAT)。
显示适配器(display adapter)是一种硬件设备(例如独立显卡),然而系统也可以用软件显示适配器来模拟硬件的图形处理功能。一个系统中可能会存在数个适配器(比如装有数块显卡)。适配器用接口IDXGIAdapter来表示。我们可以用下面的代码来枚举一个系统中的所有适配器:
1 | |
称每一台显示设备都是一个显示输出(display output,有的文档也作adapter output,适配器输出)实例,用IDXGIOutput接口来表示。每个适配器都与一组显示输出相关联。通过以下代码,我们就可以枚举出与某块适配器关联的所有显示输出:
1 | |
“Microsoft Basic Render Driver(Microsoft基本呈现驱动程序)”是Windows8及后续系统版本中包含的软件适配器。
在系统显卡驱动正常工作的情况下,它不会关联任何显示输出。
每种显示设备都有一系列它所支持的显示模式,可以用下列DXGI_MODE_DESC结构体中的数据成员来加以表示:
1 | |
一旦确定了显示模式的具体格式(DXGI_FORMAT),我们就能通过下列代码,获得某个显示输出对此格式所支持的全部显示模式:
1 | |
在进入全屏模式之时,枚举显示模式就显得尤为重要。为了获得最优的全屏性能,我们所指定的显示模式(包括刷新率)一定要与显示器支持的显示模式完全匹配。
资源驻留
在Direct3D 12中,应用程序通过控制资源在显存中的去留,主动管理资源的驻留情况(即residency。无论资源是否本已位于显存中,都可对其进行管理。在Direct3D 11中则由系统自动管理)。该技术的基本思路为使应用程序占用最小的显存空间。这是因为显存的空间有限,很可能不足以容下整个游戏的所有资源,或者用户还有运行中的程序也在同时使用显存。这里给出一条与性能相关的提示:程序应当避免在短时间内于显存中交换进出相同的资源,这会引起过高的开销。最理想的情况是,所清出的资源在短时间内不会再次使用。游戏关卡或游戏场景的切换是关于常驻资源的好例子。
1 | |
GPU较之于显卡的地位大致相当于CPU较之于主板。相应的,GPU控制的显存基本相当于CPU控制的内存,而后者在本书中也常被称为系统内存(system memory)。CPU内部有多级缓存与寄存器,分别用于缓存指令与控制CPU;GPU内部亦有缓存与寄存器,分别用于缓存纹理、缓存着色器指令等以及控制GPU。有的文献在划分GPU的组成结构时,会把GPU的寄存器及其控制的内存统称为GPU memory (GPU存储器)。
CPU与GPU间的交互
同步是一种我们不乐于执行的操作,因为这意味着一种处理器要以空闲状态等待另一种处理器完成某些任务。
每个GPU都至少维护着一个命令队列(command queue,本质上是环形缓冲区,即ring buffer)。借助Direct3D API,CPU可利用命令列表(command list)将命令提交到这个队列中去。当一系列命令被提交至命令队列之时,它们并不会被GPU立即执行。由于GPU可能正在处理先前插入命令队列内的命令,因此,后来新到的命令会一直在这个队列之中等待执行。
相对于Direct3D 12而言,Direct3D 11支持两种绘制方式:即立即渲染(immediate rendering,利用immediate context实现)以及延迟渲染(deferred rendering,利用deferred context实现)。前者将缓冲区中的命令直接借驱动层发往GPU执行,后者则与本文中介绍的命令列表模型相似(但执行命令列表时仍然要依赖immediate context)。前者延续了Direct3D 11之前一贯的绘制方式,而后者则为Direct3D 11中新添加的绘制方式。到了Direct3D 12便取消了立即渲染方式,完全采用“命令列表->命令队列”模型,使多个命令列表同时记录命令,借此充分发挥多核心处理器的性能。可见,Direct3D 11在绘制方面乃承上启下之势,而Direct3D 12则进行了彻底的革新。
在Direct3D 12中,命令队列被抽象为ID3D12CommandQueue接口来表示。要通过填写D3D12_COMMAND_QUEUE_DESC结构体来描述队列,再调用ID3D12Device::CreateCommandQueue方法创建队列。
1 | |
IID_PPV_ARGS辅助宏的定义如下:
1 | |
ExecuteCommandLists是一种常用的ID3D12CommandQueue接口方法,利用它可将命令列表里的命令添加到命令队列之中:
1 | |
继承于ID3D12CommandList接口的ID3D12GraphicsCommandList接口封装了一系列图形渲染命令,有数种方法向命令列表添加命令:
1 | |
命令分配器(command allocator)存储记录在命令列表内的命令。
创建命令分配器:
1 | |
创建命令列表:
1 | |
我们可以创建出多个关联于同一命令分配器的命令列表,但是不能同时用它们来记录命令。因此,当其中的一个命令列表在记录命令时,必须关闭同一命令分配器的其他命令列表。
可以通过ID3D12GraphicsCommandList::Reset方法,安全地复用命令列表占用的相关底层内存来记录新的命令集。重置命令列表并不会影响命令队列中的命令,因为相关的命令分配器仍在维护着其内存中被命令队列引用的系列命令。
1 | |
向GPU提交了一整帧的渲染命令后,使用ID3D12CommandAllocator::Reset方法复用命令分配器中的内存绘制下一帧。类似std::vector::clear方法(使向量的size归零,但是仍保持其当前的capacity),命令队列可能会引用命令分配器中的数据,在没有确定GPU执行完命令分配器中的所有命令之前,千万不要重置命令分配器。
1 | |
实现GPU和CPU间的同步:强制CPU等待,直到GPU完成所有命令的处理,达到某个指定的围栏点(fence point)为止。我们将这种方法称为刷新命令队列(flushing the command queue),可以通过围栏(fence)来实现这一点。围栏用ID3D12Fence接口来表示。
1 | |
如何用一个围栏来刷新命令队列:
1 | |
在第7章以前也只能暂时使用这个简单的办法了。
资源转换
当GPU的写操作还没有完成抑或甚至还没有开始,却开始读取资源,便会导致资源冒险(resource hazard)。为此,Direct3D专门针对资源设计了一组相关状态。资源在创建伊始会处于默认状态,该状态将一直持续到应用程序通过Direct3D将其转换(transition)为另一种状态为止。例如,如果要对某个资源(比如纹理)执行写操作时,需要将它的状态转换为渲染目标状态;而要对该纹理进行读操作时,再把它的状态变为着色器资源状态。根据Direct3D给出的转换信息,GPU就可以采取适当的措施避免资源冒险的发生。譬如,在读取某个资源之前,它会等待所有与之相关的写操作执行完毕。
通过命令列表设置转换资源屏障(transition resource barrier)数组,即可指定资源的转换;当我们希望以一次API调用来转换多个资源的时候,这种数组就派上了用场。
1 | |
Direct3D 12中的许多结构体都有其对应的扩展辅助结构变体(variation),考虑到使用上的方便性,我们更偏爱于运用那些变体。以CD3DX12作为前缀的变体全都定义在d3dx12.h头文件当中,这个文件并不属于DirectX 12 SDK的核心部分,但是可以通过微软的官方网站下载获得。为了方便起见,本书源代码的Common目录里附有一份d3dx12.h头文件。
命令与多线程
Direct3D 12的设计目标是为用户提供一个高效的多线程环境,命令列表也是一种发挥Direct3D多线程优势的途径。对于内含许多物体的庞大场景而言,仅通过一个构建命令列表来绘制整个场景会占用不少的CPU时间。因此,可以采取一种并行创建命令列表的思路。例如,我们可以创建4条线程,每条分别负责构建一个命令列表来绘制25%的场景物体。
以下是一些在多线程环境中使用命令列表要注意的问题:
命令列表并非自由线程(not free-threaded)对象。也就是说,多线程既不能同时共享相同的命令列表,也不能同时调用同一命令列表的方法。所以,每个线程通常都只使用各自的命令列表。
命令分配器亦不是线程自由的对象。这就是说,多线程既不能同时共享同一个命令分配器,也不能同时调用同一命令分配器的方法。所以,每个线程一般都仅使用属于自己的命令分配器。
命令队列是线程自由对象,所以多线程可以同时访问同一命令队列,也能够同时调用它的方法。特别是每个线程都能同时向命令队列提交它们自己所生成的命令列表。
出于性能的原因,应用程序必须在初始化期间,指出用于并行记录命令的命令列表最大数量。
为了简单起见,本书不会使用多线程技术。完成本书的阅读后,读者可以通过查阅SDK中的Multithreading12示例来学习怎样并行生成命令列表。如果希望应用程序充分利用系统资源,应该通过多线程技术来发挥CPU多核心的并行处理能力。
初始化Direct3D
对Direct3D进行初始化的步骤:
- 用D3D12CreateDevice函数创建ID3D12Device接口实例。
- 创建一个ID3D12Fence对象,并查询描述符的大小。
- 检测用户设备对4X MSAA质量级别的支持情况。
- 依次创建命令队列、命令列表分配器和主命令列表。
- 描述并创建交换链。
- 创建应用程序所需的描述符堆。
- 调整后台缓冲区的大小,并为它创建渲染目标视图。
- 创建深度/模板缓冲区及与之关联的深度/模板视图。
- 设置视口(viewport)和裁剪矩形(scissor rectangle)。
计时与动画
MSDN对QueryPerformanceCounter函数作有如下备注:“按道理来讲,对于一台具有多个处理器的计算机而言,无论在哪一个处理器上调用此函数都应返回当前时刻的计数值。然而,由于基本输入/输出系统(BIOS)或硬件抽象层(HAL)上的缺陷,导致了在不同的处理器上可能会得到不同的结果。
全书的演示程序都使用了d3dUtil.h、d3dUtil.cpp、d3dApp.h和d3dApp.cpp中的框架代码,可以从本书的官方网站下载到这些文件。d3dUtil.h和d3dUtil.cpp文件中含有程序所需的实用工具代码,d3dApp.h和d3dApp.cpp文件内包含用于封装Direct3D示例程序的Direct3D应用程序类核心代码。
在析构函数中刷新命令队列的原因是:在销毁GPU引用的资源以前,必须等待GPU处理完队列中的所有命令。否则,可能造成应用程序在退出时崩溃。
对于本书的所有示例程序来说,我们每次都会重写D3DApp中的6个虚函数。这6个函数用于针对特定的示例来实现所需的具体功能。这种设定的好处是把初始化代码、消息处理等流程都统一实现在D3DApp类中,继而使我们可以把精力集中在特定例程中的关键代码之上。以下是对这6个框架方法的概述。
- Initialize:通过此方法为程序编写初始化代码,例如分配资源、初始化对象和建立3D场景等。
- MsgProc:该方法用于实现应用程序主窗口的窗口过程函数(procedurefunction)。
- CreateRtvAndDsvDescriptorHeaps:此虚函数用于创建应用程序所需的RTV和DSV描述符堆。
- OnResize:当D3DApp::MsgProc函数接收到WM_SIZE消息时便会调用此方法。
- Update:在绘制每一帧时都会调用该抽象方法,我们通过它来随着时间的推移而更新3D应用程序(如呈现动画、移动摄像机、做碰撞检测以及检查用户的输入等)。
- Draw:在绘制每一帧时都会调用的抽象方法。我们在该方法中发出渲染命令,将当前帧真正地绘制到后台缓冲区中。当完成帧的绘制后,再调用IDXGISwapChain::Present方法将后台缓冲区的内容显示在屏幕上。
第5章 渲染流水线
如果给出一台具有确定位置和朝向的虚拟摄像机(virtual camera)以及某个3D场景的几何描述,那么渲染流水线则是以此虚拟摄像机为视角进行观察,并据此生成给定3D场景2D图像的一整套处理步骤。
从观察效果上看,平行线最终会相交于消失点(vanishing point,又称灭点)。
实体3D对象是借助三角形网格(triangle mesh)来近似表示的,因而我们要以三角形作为3D物体建模的基石。
每款显示器所能发出的红、绿、蓝三色光的强度都是有限的。为了便于描述光的强度,我们常将它量化为范围在0~1归一化区间中的值。0代表无强度,1则表示强度最大,处于两者之间的值就表示对应的中间强度。例如,强度值(0.25, 0.67,1.0)就表明此光线由强度为25%的红色光、强度为67%的绿色光以及强度为100%的蓝色光混合而成。
颜色向量也有它们自己专属的颜色运算,即分量式(modulation或componentwise)乘法。
我们通常还会用到另一种名为alpha分量(alpha component)的颜色分量。alpha分量常用于表示颜色的不透明度(opacity。值为0.0表示完全透明,值为1.0表示不透明)。
一般来说,128位颜色值常用于高精度的颜色运算(例如位于像素着色器中的各种运算)。在这种情况下,由于运算所用的精度较高,因此可有效降低计算过程中所产生的误差。但是,最终存储在后台缓冲区中的像素颜色数据,却往往都是以32位颜色值来表示。而目前的物理显示设备仍不足以充分发挥出更高色彩分辨率的优势。

输入装配器(Input Assembler,IA)阶段会从显存中读取几何数据(顶点和索引,vertex and index),再将它们装配为几何图元(geometric primitive,亦译作几何基元,如三角形和线条这种构成图形的基本元素)。
在Direct3D中,我们要通过一种名为顶点缓冲区(vertex buffer)的特殊数据结构,将顶点与渲染流水线相绑定。顶点缓冲区利用连续的内存来存储一系列顶点。
通过指定图元拓扑(primitive topology,或称基元拓扑)来告知Direct3D如何用顶点数据来表示几何图元。
经过观察可以发现,在三角形带中,次序为偶数的三角形与次序为奇数三角形的绕序(winding order,也译作环绕顺序等,即装配图元的顶点顺序为逆时针或顺时针方向)是不同的,这就是剔除(culling,亦称消隐)问题的由来。为了解决这个问题,GPU内部会对偶数三角形中前两个顶点的顺序进行调换,以此使它们与奇数三角形的绕序保持一致。
先创建一个顶点列表和一个索引列表。在顶点列表中收录一份所有独立的顶点,并在索引列表中存储顶点列表的索引值,这些索引定义了顶点列表中的顶点是如何组合在一起,从而构成三角形的。
待图元被装配完毕后,其顶点就会被送入顶点着色器阶段(vertex shader stage,简记作VS)。我们可以把顶点着色器看作一种输入与输出数据皆为单个顶点的函数。每个要被绘制的顶点都须经过顶点着色器的处理再送往后续阶段。
我们可以利用顶点着色器来实现许多特效,例如变换、光照和位移贴图(displacement mapping,也译作置换贴图。map有映射之意,因此也有译作位移映射,类似的还有在后面将见到的纹理贴图、法线贴图等)。
曲面细分阶段(tessellation stages)是利用镶嵌化处理技术对网格中的三角形进行细分(subdivide),以此来增加物体表面上的三角形数量。再将这些新增的三角形偏移到适当的位置,使网格表现出更加细腻的细节。
几何着色器(geometry shader stage,GS)阶段是可选阶段。几何着色器接受的输入应当是完整的图元。几何着色器的主要优点是可以创建或销毁几何体。几何着色器的常见拿手好戏是将一个点或一条线扩展为一个四边形。
裁剪。苏泽兰(萨瑟兰德)-霍奇曼裁剪算法(Sutherland-Hodgman clipping algorithm,前者Ivan Sutherland是图形界的奠基人,可以了解一下)。
光栅化阶段(rasterization stage,RS,亦有将rasterization译作像素化或栅格化)的主要任务是为投影至屏幕上的3D三角形计算出对应的像素颜色。
当裁剪操作完成之后,硬件会通过透视除法将物体从齐次裁剪空间变换为规格化设备坐标(NDC)。一旦物体的顶点位于NDC空间内,构成2D图像的2D顶点坐标就会被变换到后台缓冲区中称为视口(viewport)的矩形里。
在我们选择的这种约定当中(也就是计算三角形法线的方法),根据观察者的视角看去,顶点绕序为顺时针方向的三角形为正面朝向,而顶点绕序为逆时针方向的三角形为背面朝向。可以通过DX设定这个约定。
像素着色器(pixel shader,PS)是一种由GPU来执行的程序。它会针对每一个像素片段(pixel fragment,亦有译作片元)进行处理(即每处理一个像素就要执行一次像素着色器),并根据顶点的插值属性作为输入来计算出对应的像素颜色。
通过像素着色器生成的像素片段会被移送至渲染流水线的输出合并(Output Merger,OM)阶段。
第6章 利用Direct3D绘制几何体
在着色器代码中,未标明索引的语义将默认其索引值为0。
输入布局:
1 | |
为了使GPU可以访问顶点数组,就需要把它们放置在称为缓冲区(buffer)的GPU资源(ID3D12Resource)里。我们把存储顶点的缓冲区叫作顶点缓冲区(vertexbuffer)。缓冲区的结构比纹理更为简单:既非多维资源,也不支持mipmap、过滤器以及多重采样等技术。当需要向GPU提供如顶点这类数据元素所构成的数组时,我们便会使用缓冲区。
在Direct3D 12中,所有的资源均用ID3D12Resource接口表示。相比之下,Direct3D 11则采用如ID3D11Buffer与ID3D11Texture2D等多种不同的接口来表示各种不同的资源。
对于静态几何体(static geometry,即每一帧都不会发生改变的几何体)而言,我们会将其顶点缓冲区置于默认堆(D3D12_HEAP_TYPE_DEFAULT)中来优化性能。一般说来,游戏中的大多数几何体(如树木、建筑物、地形和动画角色)都是如此处理。
CPU不能向默认堆中的顶点缓冲区写入数据,需要上传缓冲区作为中介,通过把资源提交至上传堆,才得以将数据从CPU复制到GPU显存中。
与顶点相似,为了使GPU可以访问索引数组,就需要将它们放置于GPU的缓冲区资源(ID3D12Resource)内。我们称存储索引的缓冲区为索引缓冲区(index buffer)。
为了将顶点缓冲区绑定到渲染流水线上,我们需要给这种资源创建一个顶点缓冲区视图(vertex buffer view)。与RTV(render target view,渲染目标视图)不同的是,我们无须为顶点缓冲区视图创建描述符堆。
索引缓冲区同理。
在Direct3D中,编写着色器的语言为高级着色语言(High Level Shading Language,HLSL),其语法与C++十分相似,这使得它较易于学习。
注意,SV_POSITION语义比较特殊(SV代表系统值,即system value),它所修饰的顶点着色器输出元素存有齐次裁剪空间中的顶点位置信息。因此,我们必须为输出位置信息的参数附上SV_POSITION语义,使GPU可以在进行例如裁剪、深度测试和光栅化等处理之时,借此实现其他属性所无法介入的有关运算。
系统值语义是在Direct3D 10引入的。Direct3D 10及其后续版本中的SV_Position语义,与Direct3D 9中的POSITION语义等价。其它语义的对照关系与使用方法请参考《Semantics》(bb509647)。
如果没有使用几何着色器(我们会在第12章中介绍这种着色器),那么顶点着色器必须用SV_POSITION语义来输出顶点在齐次裁剪空间中的位置,因为(在没有使用几何着色器的情况下)执行完顶点着色器之后,硬件期望获取顶点位于齐次裁剪空间之中的坐标。如果使用了几何着色器,则可以把输出顶点在齐次裁剪空间中位置的工作交给它来处理。
像素着色器返回一个4D颜色值,而位于此函数参数列表后的SV_TARGET语义则表示该返回值的类型应当与渲染目标格式(render target format)相匹配(该输出值会被存于渲染目标之中)。
与顶点缓冲区和索引缓冲区不同的是,常量缓冲区通常由CPU每帧更新一次。举个例子,如果摄像机每帧都在不停地移动,那么常量缓冲区也需要在每一帧都随之以新的视图矩阵而更新。所以,我们会把常量缓冲区创建到一个上传堆而非默认堆中,这样做能使我们从CPU端更新常量。
通常来讲,在绘制调用开始执行之前,我们应将不同的着色器程序所需的各种类型的资源绑定到渲染流水线上。实际上,不同类型的资源会被绑定到特定的寄存器槽(register slot)上,以供着色器程序访问。比如说,前文代码中的顶点着色器和像素着色器需要的是一个绑定到寄存器b0的常量缓冲区。在本书的后续内容中,我们会用到这两种着色器更高级的配置方法,以使多个常量缓冲区、纹理(texture)和采样器(sampler)都能与各自的寄存器槽相绑定。
根签名(root signature)定义的是:在执行绘制命令之前,那些应用程序将绑定到渲染流水线上的资源,它们会被映射到着色器的对应输入寄存器。
如果更改了根签名,则会失去现存的所有绑定关系。也就是说,在修改了根签名后,我们需要按新的根签名定义重新将所有的对应资源绑定到渲染流水线上。尽量减少每帧渲染过程中根签名的修改次数。
阶段都是可编程的,但是有些特定环节却只能接受配置。例如配置渲染流水线中光栅化阶段。
大多数控制图形流水线状态的对象被统称为流水线状态对象(Pipeline State Object,PSO),用ID3D12PipelineState接口来表示。
ID3D12PipelineState对象集合了大量的流水线状态信息。为了保证性能,我们将所有这些对象都集总在一起,一并送至渲染流水线。通过这样的一个集合,Direct3D便可以确定所有的状态是否彼此兼容,而驱动程序则能够据此而提前生成硬件本地指令及其状态。在Direct3D 11的状态模型中,这些渲染状态片段都是要分开配置的。然而这些状态实际都有一定的联系,以致如果其中的一个状态发生改变,那么驱动程序可能就要为了另一个相关的独立状态而对硬件重新进行编程。由于一些状态在配置流水线时需要改变,因而硬件状态也就可能被频繁地改写。为了避免这些冗余的操作,驱动程序往往会推迟针对硬件状态的编程动作,直到明确整条流水线的状态发起绘制调用后,才正式生成对应的本地指令与状态。但是这种延迟操作需要驱动在运行时进行额外的记录工作,即追踪状态的变化,而后才能在运行时生成改写硬件状态的本地代码。在Direct3D 12的新模型中,驱动程序可以在初始化期间生成对流水线状态编程的全部代码,这便是我们将大多数的流水线状态指定为一个集合所带来的好处。
第7章 利用Direct3D绘制几何体(续)
为了解决每帧结尾刷新命令队列导致的低效率(GPU、CPU空闲时间):以CPU每帧都需更新的资源作为基本元素,创建一个环形数组(circular array,也有译作循环数组)。我们称这些资源为帧资源(frame resource),而这种循环数组通常是由3个帧资源元素所构成的。CPU比GPU提前处理两帧,以确保GPU可持续工作。
帧资源可保证持续向GPU提供数据,当GPU在处理第n帧的时候,CPU可以继续构建和提交绘制第n+1和n+2帧的命令。但帧资源不可保证不发生等待,若CPU速度远快于GPU,CPU必有空闲时间。空闲时间可以被游戏的其它部分利用。
把单次绘制调用过程中,需要向渲染流水线提交的数据集称为渲染项(render item)。
渲染项一般包括绘制单个物体需要的顶点缓冲区、索引缓冲区、常量数据、图元类型、DrawIndexedInstanced方法的参数。一个几何物体可能由多个渲染项组成。
基于资源的更新频率对常量数据进行分组。不要在着色器内使用过多的常量缓冲区。
7.6详细讲解了根签名的使用。
第8章 光照
可以把材质看作是确定光照与物体表面如何进行交互的属性集。
本书中(以及大多数实时应用程序)所采用的光照模型均为局部光照模型(local illumination model),每个物体的光照皆独立于其他物体,忽略来自场景中其他物体所反弹来的光。反之为全局光照模型(global illumination model)。
Phong lighting是per pixel lighting。
使用矩阵\(A\)对图形进行变换,若变换是非等比变换或剪切变换(shear transformation),变换后的法向量不再具有正交性,需要使用逆转置矩阵\((A^{-1})^T\)再对其进行变换。
微表面模型(microfacet):
可以认为理想镜面(perfect mirror)的粗糙度为0,微表面法线(micro-normal)都与宏表面法线(macro-normal)的方向相同。随着粗糙度的增加,微观表面法线的方向开始纷纷偏离宏观表面法线,由此反射光逐渐扩展为一个镜面瓣(specular lobe)。
光源方向和观察方向角平分线上的方向向量为半向量,确定了方向与半向量相同的微表面在所有微表面中所占的比例,就可以确定有多少光通过镜面反射进入观察者眼中。
记半向量\(h\)与宏表面法线\(n\)夹角为\(\theta_{h}\),粗糙度为\(m\),一种微表面法线分布的数学模型: \[ S(\theta_{h})=\frac{m+8}{8}(n\cdot h)^m \] 菲涅尔项(Fresnel Term)的Schlick approximation: \[ R_0=(\frac{n1-n2}{n1+n2})^2 \] \[ R(\theta)=R_0+(1-R_0)(1-cos\theta)^5 \] 本节使用的光照模型伪代码:
1 | |
第9章 纹理贴图
纹理贴图(texture mapping)是一种将图像数据映射到网格三角形上的技术。加载纹理,然后在着色器中对纹理进行采样。
渲染到纹理(render-to-texture)即将数据渲染到一个纹理后,再用它作为着色器资源。
针对GPU而专门设计DDS格式:
- mipmap
- GPU能自行解压的压缩格式
- 纹理数组
- cube map
- volume texture
由于块压缩算法(block compression algorithm)要以4x4的像素块为基础进行处理,所以纹理的尺寸必须为4的倍数。
第10章 混合
混合(blending)将当前要光栅化的source pixel与之前已光栅化至后台缓冲区的destination pixel相融合,可以用来绘制半透明等效果。alpha分量通常用来调节透明度。
在绘制混合物体时,需要禁止深度写入,保留深度读取与深度测试,确保混合物体不能遮挡非混合物体,非混合物体可以遮挡混合物体。
第11章 模板
模板(stencil)缓冲区与深度缓冲区、后台缓冲区分辨率相同,像素一一对应,可以通过模板测试指定绘制区域。
实现镜像效果:
- 先绘制镜子外其它物体,然后将模板缓冲区清零
- 将镜子绘制到模板缓冲区中
- 将其他物体的镜像绘制到后台缓冲区和模板缓冲区中
- 用混合技术将镜子绘制到后台缓冲区中
双重混合:将物体的几何形状投射到平面而形成阴影时,可能会有两个甚至更多的平面阴影三角形相互重叠。若此时用透明度这一混合技术来渲染阴影,则这些三角形的重叠部分会混合多次,使之看起来更暗。可以用模板测试防止同一像素被绘制多次。
深度复杂性(depth complexity)指通过深度测试竞争,向后台缓冲区中某一特定元素写入像素片段的次数。overdraw非常影响性能。可以通过模板测试将深度复杂性可视化。本来深度测试发生于渲染流水线像素着色器阶段之后的输出合并阶段,但可以通过提前z测试(early z-test)在处理像素着色器之前进行深度测试,该功能由图形驱动负责,无法通过图形API控制。
第12章 几何着色器
几何着色器(geometry shader)输入和输出都是图元,可用于修改或舍弃图元。
将一个三角形细分为四个面积相等的三角形的几何着色器:
1 | |
alpha-to-coverage:让硬件检测像素着色器所返回的alpha值,并将其用于确定MSAA覆盖的情况。令成员D3D12_BLEND_DESC::AlphaToCoverageEnable = true来实现。
第13章 计算着色器
计算着色器(compute shader)用于实现数据并行算法,不必渲染出任何图形,因此不属于渲染流水线中的一部分(使用自己的PSO,调用称为dispatch call而不是draw call)。
将GPU用于非图形应用程序的情况称为通用GPU程序设计(General Purpose GPU programming,GPGPU programming)。
在GPU编程的过程中,根据程序具体的执行需求,可将线程划分为由线程组(thread group)构成的网格(grid)。一个线程组运行于一个多处理器之上,性能起见每个多处理器至少拥有两个线程组。
以NVIDIA的产品为例,硬件将线程组中的线程分为多个warp(每个warp中有32个线程),多处理器会以SIMD32的方式(即32个线程同时执行相同的指令序列)来处理warp。每个CUDA核心都可处理一个线程。
启动线程组:
1 | |
将两个纹理进行简单累加的计算着色器:
1 | |
调度线程ID由线程组ID与组内线程ID推算出:
1 | |
使用消费结构化缓冲区(consume structured buffer,一种输入缓冲区)与追加结构化缓冲区(append structured buffer,一种输出缓冲区),便不用再考虑索引问题:
1 | |
每个线程组都有一块称为共享内存(shared memory)或线程本地存储器(thread local storage)的内存空间,访问速度很快,但是大小有限制。
shader model 4.0(对应DirectX 10)与Shader model 5.0(对应DirectX 11)分别支持组内共享内存为16KB与32KB。
1 | |