《Effective Modern C++》笔记
42 Specific Ways to Improve Your Use of C++11 AND C++14
Scott Meyers 著
高博 译
摘录整理。
第1章 型别推导
条款1 理解型别推导
1 | |
T与ParamType两个型别推导往往不同。
情况1: ParamType是指针或引用,但不是万能引用
实参的引用会被忽略。
1 | |
情况2: ParamType 是个万能引用
采用右值来初始化万能引用会得到一个右值引用;采用左值来初始化万能引用,就会得到一个左值引用。
这里涉及引用折叠,X& &、X& &&和X&& &都折叠成类型X&;类型X&& &&折叠成X&&。(参见C++ Primer 16.2或条款28)
当遇到万能引用时,型别推导规则会区分实参是左值还是右值。而非万能引用是从来不会作这样的区分的。
向形参T&&传入实参左值,是T被推导为引用型别的唯一情形。
1 | |
情况3: ParamType既非指针也非引用
因为是值传递,引用、顶层const、volatile均忽略。
1 | |
数组实参
数组会退化为指向到其首元素的指针,除了引用方式传参的时候。
1 | |
推导数组尺寸的模板:
1 | |
函数实参
函数型别会退化为函数指针,除了引用方式传参的时候。
1 | |
条款2 理解auto型别推导
在模板型别推导和 auto型别推导可以建立起一一映射。映射仅指概念上等价,并不是编译器真的生成了该模板和语句。
1 | |
条款1的规则也适用于auto型别推导,只有一个例外。
1 | |
C++14允许使用auto来说明函数返回值需要推导、lambda表达式会在形参声明中用到auto,这些auto是在使用模板型别推导而非auto型别推导。因此以下用法是错误的。
1 | |
条款3 理解decltype
C++11的返回值型别尾序语法 (trailing return type syntax):
1 | |
C++11允许单表达式的lambda式的返回值型别推导,而C++14则将这个允许范围扩张到了一切lambda式和一切函数,可以只保留auto,但不总是正确,因为auto推导会忽略引用。C++14使用decltype(auto)解决这个问题:
1 | |
再考虑到传递右值的情况,authAndAccess函数应使用万能引用和std::forward(参见条款25):
1 | |
decltype存在艰涩的例外情况,本书不完全展开。
对于型别为T的左值表达式,除非该表达式仅有一个名字,decltype总是得出型别T&。
1 | |
条款4 掌握查看型别推导结果的方法
IDE的提示
编译器诊断信息
1
2
3
4template<typename T>
class TD; // Type Displayer
TD<decltype(x)> xType; // 因为模板未定义,所以编译器会输出包括x型别得诊断信息
// 如:error: aggregate 'TD<int> xType' has incomplete type and cannot be defined运行时输出
不同编译器实现不同。
std::type_info::name中处理型别的方式仿佛是向函数模板桉值传递形参那样,引用、顶层const、volatile会被忽略,因此并不可靠。<boost/type_index.hpp>库表现更好:1
2
3
4
5
6
7
8
9
10#include <boost/type_index.hpp>
template<typename T>
void f(const T& param)
{
using std::cout;
using boost::typeindex::type_id_with_cvr;
cout << "T = " << type_id_with_cvr<T>().pretty_name() << "\n";
cout << "param = " << type_id_with_cvr<decltype(param)>().pretty_name() << "\n";
}
第2章 auto
条款5 优先选用auto,而非显式型别声明
std::function通常比起auto又大又慢,还可能导致内存耗尽异常。
1 | |
条款6 当auto推导的型别不符合要求时,使用带显式型别的初始化物习惯用法
特例:std::vector<bool>的operator[]的返回值并不是容器中的一个元素的引用,而是std::vector<bool>::reference型别(嵌套在std::vector<bool>里的类,一个代理类)的对象。因为std::vector<bool>用一个比特表示一个bool元素,而C++禁止比特的引用。
1 | |
防止这样的代码:auto someVar = ”隐形"代理型别表达式;
带显式型别的初始化物习惯用法:
1 | |
第3章 转向现代C++
条款7 在创建对象时注意区分()和
条款2中提到过,C++有四种初始化语法。(初始化与赋值是两码事)
C++11引入大括号初始化,适用于所有场合。小括号初始化不适用于为非静态成员指定默认初始化值,等号初始化不适用于不可复制的对象(如std::atomic型别的对象)。
大括号初始化禁止内置型别的隐式窄化型别转换,如double到int。
C++最令人苦恼之解析语法(most vexing parse):任何能够解析为声明的都要解析为声明。可以用大括号初始化解决。
1 | |
只要有可能,编译器就会优先把大括号初始化语法解读为带有std::initializer_list型别形参的构造函数。(类似的,条款2曾提到,使用大括号初始化物来初始化用auto声明的变量会使推导出的型别称为std::initializer_list)(空大括号优先表示没有实参而不是空的std::initializer_list)
对于vector,使用()还是{}有很大区别,例子如下:
1 | |
条款8 优先选用nullptr,而非0或NULL
C++11以前,不要在指针型别和整型之间做重载。C++11的nullptr不具备整型类型。
nullptr的实际型别是std::nullptr_t,循环定义。
1 | |
条款9 优先选用别名声明,而非typedef
C++11引入别名声明。
更易理解:
1 | |
可以模板化:
1 | |
头文件<type_traits>有可以修改型别的工具:
1 | |
条款10 优先选用限定作用域的枚举型别,而非不限作用域的枚举型别
C++11的限定作用域的枚举防止了枚举量的名字泄漏到枚举型别所在作用域。
1 | |
此外,限定作用域的枚举型别无法隐式转换到其它型别。
C++98不限定作用域的枚举无法进行前置声明,因为无法确认其底层型别。若取值范围小会用char,更大则用更大的整数型别。这时,即使只有一个函数用到这个枚举量,修改枚举会导致整个系统重新编译。
C++11限定作用域的枚举可以前置声明,因为其底层型别默认是int,并且可以手动指定。不限定作用域枚举手动指定底层型别后也可以前置声明。
1 | |
不限作用域的枚举唯一的优点:用来取std::tuple型别的各个域更方便。
1 | |
条款11 优先选用删除函数,而非private未定义函数
阻止C++自动生成的成员函数被调用,优先选用C++11的=delete。
删除函数习惯上声明为public,当被错误使用时报错信息更明确。
非成员函数可以定义为删除函数,借此可以禁止非成员函数的指定重载版本。
特化函数模板(包括特化成员函数模板)可以定义为删除函数。
条款12 为意在改写的函数添加override声明
override的要求:
- 基类中的函数必须是虚函数。
- 基类和派生类中的函数名字必须完全相同(析构函数例外)。
- 基类和派生类中的函数形参型别必须完全相同。
- 基类和派生类中的函数常量性(constness)必须完全相同。
- 基类和派生类中的函数返回值和异常规格必须兼容。
- 基类和派生类中的函数引用饰词(reference qualifier)必须完全相同。(C++11新增)
1 | |
C++新增了两个语境关键字(contextual keyword):override和final。语言保留这两个关键字,但仅在特定语境下保留,以下代码升级到C++11后依然合法。
条款13 优先选用const_iterator, 而非iterator
从const_ iterator到iterator不存在可移植的型别转换,连static_cast及reinterpret_ cast也不行。C++98和C++11皆然。
由于在标准化过程中的短视,C++11仅添加了非成员函数版本的begin和end,而没有添加cbegin、cend、rbegin、rend、crbegin和crend。C++14 纠正了这种短视。
条款14 只要函数不会发射异常,就为其加上noexcept声明
C++98异常规格已被废弃,C++11只关心是否发射异常。
noexcept声明使优化器可以更好地优化,不需要在异常传出函数的前提下,将执行期栈保持在可开解状态;也不需要在异常溢出函数的前提下,保证所有其中的对象以其被构造顺序的逆序完成析构。
C++98中std::vector的扩容做法是先把元素从旧内存复制到新内存,再析构旧内存中的对象。这个做法使push_back提供了强异常安全保证:若复制过程中抛出了异常,原对象保持原样不变。C++11引入了移动语义,仅在移动操作不会发射异常(带有noexcept声明)的前提下,push_back等函数会把C++98中的赋值操作替换为C++11中的移动操作。
默认地,内存释放函数和所有的析构函数(无论是用户定义的,还是编译器自动生成的)都隐式地具备noexcept性质。这么一来,它们就无须加上noexcept声明了。
析构函数未隐式地具备noexcept性质的唯一场合:所在类中有数据成员(包括继承而来的成员,以及在其他数据成员中包含的数据成员)的型别显式地将其析构函数声明为可能发射异常的,为其加上
noexcept(false)声明。这样的析构函数很少见,标准库里一个也没有,而如果标准库使用了某个对象(例如,被包含在容器内,或被传递给某个算法),而其析构函数发射了异常,则该程序行为是未定义的。
有理由使得带有noexcept声明的函数依赖于缺乏noexcept保证的代码(调用不带noexcept声明的来此C或者C++98的函数),C++允许此类代码通过编译,并且编译器通常不会就此生成警告。
条款15 只要有可能使用constexpr,就使用它
对于对象,constexpr代表不仅是const而且在编译阶段已知,因此可以放置在只读内存以进行优化,可以用于数组尺寸、枚举量的值、对齐规格等。
对于函数,constexpr代表函数在调用时若传入的所有参数均是编译期常量,则产出编译期常量;若传入的参数含有直至运行期才知晓的值,则产出运行期值,与普通函数无异。
C++11中,constexpr函数不得包含多于一个可执行语句,即一条return语句;constexpr函数被隐式声明为const,无法修改对象的非mutable数据成员;返回型别void不是字面型别。C++14放宽以上限制。
字面型别即可以持有编译期可以决议的值的型别,用户自定义型别同样可能也是字面型别,因为它的构造函数和其他成员函数可能也是constexpr函数。
条款16 保证const成员函数的线程安全性
对于单个要求同步的变量或内存区域,使用std::atomic足够且性能更好。
如果有两个或更多个变量或内存区域需要作为一整个单位进行操作时,应使用互斥量。
条款17 理解特种成员函数的生成机制
特种成员函数即C++会自行生成的成员函数,包括默认构造函数、析构函数、复制构造函数,复制赋值运算符、移动构造函数、移动赋值运算符。
自动生成的C++移动构造函数和移动赋值运算符执行作用于非静态成员的按成员移动操作。按成员移动由两部分组成的,一部分是在支持移动操作的成员上执行的移动操作,另一部分是在不支持移动操作的成员上执行的复制操作。
两种复制操作是彼此独立的,声明了其中一个,并不会阻止编译器生成另一个。
两种移动操作并不彼此独立,声明了其中一个,就会阻止编译器生成另一个。
声明了复制操作,不再会生成移动操作了。
声明了移动操作,复制操作会废除(=delete)。
大三律(Rule of Three):如果声明了复制构造函数、复制赋值运算符、析构函数中的任何个,就得同时声明所有个。
默认构造函数:仅当类中不包含声明的构造函数时才生成。
析构函数:仅当类中不包含声明的析构函数时才生成。仅当基类的析构函数为虚,派生类的析构函数才为虚。默认为noexcept。
复制构造函数:当该类未声明复制构造函数时生成。声明移动操作会导致其被废除。已声明复制赋值运算符或析构函数时,仍然生成复制构造函数已经成为了被废弃的行为。
复制赋值运算符:当该类未声明复制赋值运算符时生成。声明移动操作会导致其被废除。已声明复制构造函数或析构函数时,仍然生成复制赋值运算符已经成为了被废弃的行为。
移动构造函数和移动赋值运算符:当该类未声明析构函数、复制操作、移动操作时生成。
成员函数模板在任何情况下都不会抑制特种成员函数的生成。(条款26与之相关)
第4章 智能指针
条款18 使用std::unique_ptr管理具备专属所有权的资源
std::unique_ptr不允许复制,是只移型别。
std::unique_ptr可能不调用托管资源析构函数的情况:
- 异常传播开影响到某个线程的主函数
- 违反了noexcept异常规格
std::abort、std::_Exit、std::exit、std::quick_exit(必定不调用局部对象析构函数)
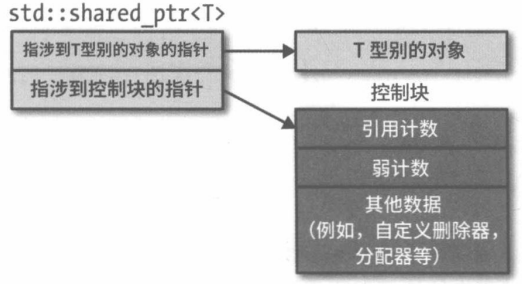
条款19 使用std::shared_ptr管理具备共享所有权的资源
std::shared_ptr可以通过访问某资源的引用计数来确定是否自己是最后一个指涉到该资源的。
引用计数带来的性能影响:
- 尺寸是裸指针的两倍(具体看实现)
- 引用计数的内存必须动态分配
- 引用计数的递增和递减必须是原子操作
与std::unique_ptr不同,std::shared_ptr的析构器型别不是智能指针型别的一部分,更灵活。
1 | |
与std::unique_ptr不同,自定义析构器不会改变std::shared_ptr的尺寸,无论析构器是怎样的型别,std::shared_ptr对象的尺寸都相当于裸指针的两倍。
避免将裸指针传递给一个std::shared_ptr的构造函数,以免创建多个控制块、拥有多个引用计数。
创建多控制块情形一:
1 | |
创建多控制块情形二:
1 | |
可以由std::unique_ptr构造std::shared_ptr,反之不成立。
有std::unique_ptr<T[]>,没有std::shared_ptr<T[]>。
条款20 对于类似std::shared_ptr但有可能空悬的指针使用std:weak_ptr
std::weak_ptr并不是一种独立的智能指针,而是std::shared_ptr的一种扩充,一般通过后者创建。
1 | |
std::weak_ptr可用于缓存、观察者模式、避免循环引用等情况。
条款21 优先选用std::make_unique和std::make_shared,而非直接使用new
std::make_shared在C++11加入,std::make_unique在C++14加入。
1 | |
new可能导致内存泄漏:
1 | |
make系列函数的缺点:
- 无法自定义析构器。
- 无法完美转发大括号初始化物(对形参进行完美转发时使用圆括号)。
对于std::shared_ptr,make系列函数额外的缺点:
不适用于有自身版本的opeator new和operator delete的类。因为
std::allocate_shared要求的内存数量并不等于动态分配对象的尺寸,而是该尺寸的基础上加上控制块的尺寸(参见条款19图)。std::make_shared使std::shared_ptr的控制块和托管对象在同一内存块上分配。此时,就算最后一个std::shared_ptr析构,只要还存在std::weak_ptr,托管对象内存也不会释放,因为与其关联的控制块内存没有释放(控制块有弱计数)。
弱计数(参见条款19图)对指涉到该控制块的
std::weak_ptr进行计数。实际上,弱计数的值并不始终等于指涉到控制块的
std::weak_ptr的数量,因为库的实现者已经找到了某些方法向弱计数加入额外信息以促进更好的代码生成。
条款22 使用Pimpl习惯用法时,将特殊成员函数的定义放到实现文件中
Pimpl即pointer to implementation。
1 | |
现代C++中Pimpl通常使用std::unique_ptr实现,但是注意,应将析构函数和移动操作(引发析构)的定义放在实现文件中的不完整型别的定义之后,因为在实施delete运算符之前会使用C++11中的static_assert去确保裸指针未指涉到非完整型别。
对于
std::unique_ptr而言,析构器型别是智能指针型别的一部分,这使得编译器会产生更小尺寸的运行期数据结构以及更快速的运行期代码。如此高效带来的后果是,欲使用编译器生成的特种函数(例如,析构函数或移动操作),就要求其指涉到的型别必须是完整型别。对于
std::shared_ptr而言,析构器的型别并非智能指针型别的一部分,这就需要更大尺寸的运行时期数据结构以及更慢一些的目标代码,但在使用编译器生成的特种函数时,其指涉到的型别却并不要求是完整型别。
第5章 右值引用、移动语义和完美转发
移动语义使得创建只移型别对象成为可能,这些型别包括std::unique_ ptr、std::future、std:: thread等。
形参总是左值,即使其型别是右值引用。
条款23 理解std::move和std::forward
这两者在运行期无所作为,不会生成任何可执行代码,仅仅执行强制型别转换。
std::move只做一件事,把实参强制转换成右值。
1 | |
std::move不保证经过其强制型别转换后的对象具备可移动的能力。针对常量对象执行的移动操作将一声不响地变换成复制操作,例如左值const std::string转换为右值const std::string,仍调用复制构造函数。
因为形参总是左值,std::forward只在传入形参的实参使用右值初始化时,把实参强制转化为右值。
条款24 区分万能引用和右值引用
当&&涉及型别推导,如auto、函数模板形参(比如形如T&&)时,是万能引用。
1 | |
条款25 针对右值引用实施std::move,针对万能引用实施std::forward
在按值返回的函数中,如果返回的是绑定到一个右值引用或一个万能引用的对象,则当你返回该引用时,应该对其实施std::move或者std::forward。
返回值优化 (return value optimization,
RVO):当局部对象型别和函数返回值型别相同且返回值就是局部对象本身(而不是引用),编译器可以选择在一个按值返回的函数里省略对局部对象的复制(或者移动),直接在为函数返回值分配的内存上创建局部变量。当编译器选择不执行RVO时,返回对象必须作为右值处理,相当于std:: move隐式地被实施于返回的局部对象上。所以若局部对象可能适用于RVO,请勿针对其实施std::move或std:: forward。
有人对RVO实施在局部对象时,权据局部对象具名或不具名(亦即临时)的特性进行了区分,限制了 RVO对不具名对象的使用,并将其对具名对象实施者,特别地称为具名返回值优化(named return value optimization, NRVO)。
1 | |
条款26 避免依万能引用型别进行重载
形参为万能引用的函数和几乎任何型别都会产生精确匹配(条款30描述了几种不属于该情况的实参),不要把万能引用作为重载候选型别。
1 | |
完美转发构造函数会造成严重问题,对于非常量的左值型别而言,它一般会形成相对于复制构造函数的更佳匹配,并且它们还会劫持派生类中对基类的复制和移动构造函数的调用(调用基类的完美转发构造函数)。
条款27 熟悉依万能引用型别进行重载的替代方案
放弃重载
传递
const T&型别的形参代替万能引用传值代替万能引用
标签分派
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 对条款26中代码的改进
template<typename T>
void logAndAdd(T&& name)
{
1ogAndAddImpl(std::forward<T>(name),
std::is_integral<std::remove_reference_t<T>>());
}
template<typename T>
void logAndAddImp1(T&& name, std::false_type)
{
auto now = std::chrono::system_clock::now();
log(now, "logAndAdd" );
names.emplace(std::forward<T>(name));
}
std::string nameFromIdx(int idx);
void logAndAddImpl(int idx, std::true_type)
{
logAndAdd(nameFromIdx(idx)); // 委托给前一个重载版本
}对接受万能引用的模板施加限制
std::enable_if可以强制编译器表现出来的行为如同特定的模板不存在一般。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20class Person {
public:
template<typename T,
typename = typename std::enable_if<
!std::is_intergral_v<std::remove_reference_t<T>>
&&
!std::is_base_of_v<Person, std::decay_t<T>>
>::type
>
explicit Person(T&& n) : name(std::forward<T>(n))
{
// ...
}
explicit Person(int idx) : name(nameFromIdx(idx))
{
// ...
}
private:
std::string name;
};SFINAE是使得
std::enable_if得以运作的技术。
条款28 理解引用折叠
万能引用就是在型别推导的过程会区别左值和右值,以及会发生引用折叠的语境中的右值引用。
禁止声明引用的引用,但编译器却可以在特殊的语境中产生引用的引用,模板实例化就是这样的语境之一。当编译器生成引用的引用时,引用折叠机制便支配了接下来发生的事情。
特殊的四个语境:
- 模板实例化
- auto变量的型别生成
- 生成和使用typedef和别名声明
- decltype的运用
引用折叠规则:如果任一引用为左值引用,则结果为左值引用。否则(即两个皆为右值引用)结果为右值引用。
1 | |
条款29 假定移动操作不存在、成本高、未使用
对于已知型别或已知对于移动语义的支持情况的代码,无需作以上假定。
移动语义不会更好的场景:
- 对象没有提供移动操作
- 移动不比复制快
- 要求不可发射异常,但移动操作未加上noexcept声明,不可用
C++11引入带有STL接口的内建数组std::array,它和std::vector等其它容器不一样,内存不在堆上,而在对象内,移动无法通过移动指针实现。因此移动和复制都是线性复杂度。
std::string采用了SSO(small string
optimization),小型字符串存储在对象的某个缓冲区内,不适用堆上分配的内存。移动不比复制快。
条款30 熟悉完美转发的失败情形
完美转发的含义是不仅转发对象,还转发其显著特征:型别、是左值还是右值,以及是否带有const或volation饰词等。
给定目标函数f和转发函数fwd:
1 | |
完美转发失败指当以某特定实参调用f会执行某操作,而用同实参调用fwd会执行不同的操作。不能实施完美转发的实参如下:
大括号初始化物
由于fwd的形参未声明为
std::initializer_list,编译器就会被禁止在fwd的调用过程中从表达式{1, 2, 3}出发来推导型别。解决办法:auto可以完成上述推导,可以先用auto声明,再传递给fwd。
1
2auto il = {1, 2, 3};
fwd(il);0和NULL用作空指针
推导为整型而非指针型别。
解决办法:用nullptr。
仅有声明的整型static const成员变量
不需要给出类中的整型static const成员变量的定义,仅需声明之。编译器会根据这些成员的值实施常数传播,从而就不必再为它们保留内存。因此不能对其取址。
1
2
3
4
5
6
7class Widget {
public:
static const std::size_t MinVals = 28;
};
std::vector<int> widgetData;
widgetData.reserve(Widget::MinVals); // 编译器绕过缺少定义的事实,直接用28替换Widget::MinVals引用在编译器生成的机器码中当指针处理,所以也不能将其传给万能引用。(有的编译器和链接器可以,但这不可移植)
解决办法:对其提供定义。
1
2
3const std::size_t Widget::MinVals;
// 这里没有指定28,因为声明和定义只需有一个提供初始化物。
// ODR(one definition rule)重载的函数名字和模板名字
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void f(int (*pf)(int));
// 或 void f(int pf(int));
int processVal(int value);
int processVal(int value, int priority);
f(processVal); // 没问题
fwd(processVal); // 错误,无法确定用哪个重载版本
template<typename T>
T workOnVal(T param)
{
// ...
}
fwd(work0nVal); //错误,无法确定用模板的哪个实例解决办法:手动指定。
1
2
3
4
5using ProcessFuncType = int (*)(int);
ProcessFuncType processValPtr = processVal;
fwd(processValPtr); // 重载指定
fwd(static_cast<ProcessFuncType>(workOnVal)); // 模板指定位域
C++标准禁止非const引用绑定到位域。
位域是由机器字的若干任意部分组成的(例如32 位int的第3到第5个比特),这样的实体是不可能有办法对其直接取址的。在硬件层次,引用和指针本是同一事物。
因此,常量引用也不可能绑定到位域,只是绑定到了复制了位域值的常规对象。
解决办法:复制位域值再转发。
1
2
3
4
5
6
7
8
9struct IPv4Header {
std::uint32_t version:4,
IHL:4,
DSCP:6,
ECN:2,
totalLength:16;
};
auto length = static_cast<std::uint16_t>(h.totalLength);
fwd(length);
第6章 lambda表达式
lambda表达式是表达式的一种,比如在下面这段代码中std::find_if的第三个实参:
1 | |
闭包是lambda式创建的运行期对象,根据不同的捕获模式,闭包会持有数据的副本或引用。在上面的代码中,闭包就是作为第三个实参在运行期传递给std::find_if的对象。
闭包类就是实例化闭包的类。每个lambda式都会触发编译器生成一个独无二的闭包类。而闭包中的语句会变成它的闭包类成员函数的可执行指令。
条款31 避免默认捕获模式
按引用的默认捕获模式可能导致空悬引用(当闭包越过了其包含的局部变量或形参的生命期)。
按值的默认捕获模式可能会使程序员误解情况(不可能直接捕获对象的成员变量,只可能捕获this指针,让对象被析构后持有空悬指针)。
条款32 使用初始化捕获将对象移入闭包
C++14为对象移动入闭包提供了直接支持。C++11中有近似达成移动捕获行为的做法。
初始化捕获 (init capture)(也叫广义lambda捕获):
1 | |
条款33 对auto&&型别的形参使用decltype,以std::forward之
C++14的泛型lambda式可以在形参规格中使用auto。
1 | |
实例化
std::forward时,使用一个右值引用型别和使用一个非引用型别,会产生相同结果。(std::forward实现参见条款28)
条款34 优先选用lambda式,而非std::bind
std::bind是C++98中std::bind1st和std::bind2nd的后继特性,在2005年TR1文档就包含了std::tr1::bind。
lambda式优点:
lambda式可读性强于
std::bind。1
2
3
4
5
6
7
8
9
10
11
12
13
14auto betweenL = [lowVal, highVal](const auto& val)
{
return lowVal <= val && val <= highVal;
}
using namespace std::placeholders;
auto betweenB = std::bind(std::logical_ and<>(),
std::bind(std::less_ equal<>(),
lowVal,
_1),
std::bind(std::less_equal<>(),
_1,
highVal));
// C++14中,标准运算符模板的模板型别实参大多数情况下可以省略不写,直接写<>std::bind调用时刻进行表达式评估求值,并将结果存储到绑定对象中,等待绑定对象调用时使用。lambda式统一在调用时刻求值,不容易造成误解。(使用计时函数时)std::bind无法进行重载决议,需要显式指定(使用函数指针类型static_cast)。编译器不太会内联通过函数指针发起的函数调用,因而更慢。std::bind默认传值,传引用需要使用std::ref;std::bind返回的绑定对象所有实参都是按引用传递的(利用完美转发)。lambda式可以直观地手动指定。
在C++14中,完全没必要用std::bind。C++11中还可以在移动捕获(C++14用初始化捕获)或绑定函数调用符模板对象(C++14的lambda式可以使用lambda形参)时使用。
第7章 并发API
C++11将并发融入了语言和库中。
熟悉其他线程API (例如,pthread或Windows线程库)的程序员有时会对C++提供的相对斯巴达式地简练的特性集感觉惊讶,但这是因为,C++对并发的支持中有一大部分是以对编译器厂商实施约束的形式提供的。在C++的历史上程序员首次可以跨越所有平台撰写具有标准行为的多线程程序。
标准库中为期值(future)准备了两个模板:
std::future和std::shared_future。在很多情况下,它们之间的区别并不重要,书中仅谈论期值概念,意思是指可以对这两种都适用。
条款35 优先选用基于任务而非基于线程的程序设计
异步方式运行函数doAsyncWork有两种选择:基于线程和基于任务。
1 | |
C++并发中线程的三种意义:
- 硬件线程。实际执行计算的线程。现代计算机体系结构会为每个CPU内核提供 一个或多个硬件线程。
- 软件线程。操作系统(无操作系统的嵌入式系统除外)用以实施跨进程管理以及进行硬件线程调度的线程。比硬件线程多,有上限。
std::thread。C++进程里的对象,用作底层软件线程的句柄。
超订(oversubscription)即就绪状态(非阻塞)的软件线程超过了硬件线程的数量,此时线程调度器会为软件线程在硬件线程上分配CPU时间片。当一个线程的时间片用完,另一个线程启动时,会执行语境切换,增加系统的总体线程管理开销。
超订难以避免。软件线程和硬件线程的比例取决于软件线程变成可运行状态的频繁程度,会动态改变(如一个线程如I/O密集型转换为计算密集型时)。因此使用std::async将管理交给标准库实现者更好。
基于线程更合适的情况:
- 需要访问底层线程实现的API。
- 需要自己根据硬件特性优化线程用法,手动管理线程耗尽、超订、负载均衡,以及新平台适配
- 实现超越C++并发API的线程技术(如在C++实现中未提供线程池的平台上实现线程池)
条款36 如果异步是必要的,则指定std::launch::async
std::async的启动策略:
std::launch::async启动策略意味着函数必须以异步方式运行,即在另一线程之上执行。std::launch::deferred启动策略意味函数只会在std::async所返回的期值的get或wait得到调用时才运行。当调用get或wait时,函数会同步运行,调用方会阻塞至函数运行结束为止。如果get或wait都没有得到调用,函数是不会运行的。
默认启动策略是两者均可(便于标准库管理线程):
1 | |
使用std::launch::async启动策略的std::async函数的实现:
1 | |
条款37 使std::thread型别对象在所有路径皆不可联结
若std::thread型别对象对应的底层线程处于已运行、阻塞、等待调度、运行结束等状态,认为其处于可联结状态(joinable)。
不可联结状态(unjoinable)的std::thread型别对象包括:
- 默认构造对象。没有可以执行的函数,也就没有对应的底层执行线程。
- 已移动对象。对应的底层执行线程被对应到另外一个对象。
- 已join对象。join之后不再对应于已运行完的底层执行线程。
- 已detach对象。断开了对象和它对应的底层执行线程之间的连接。
std::thread型别对象的析构函数被调用时,若其还是可联结状态,会导致程序终止,而不是隐式join或者隐式detach。因为C++标准委员会规定可联结的线程的析构函数导致程序终止,避免产生性能问题或失去对线程的控制导致BUG。
覆盖所有路径是很复杂的(正常走完作用域,或由return、continue、break、goto或异常跳出作用域),为了确保覆盖,使用RAII机制(即智能指针的实现方法)。标准库没有,参考实现:
1 | |
条款38 对变化多端的线程句柄析构函数行为保持关注
期值对象和std::thread对象的析构函数行为不同。
调用方、被调方和共享状态之间的关系:

条款36讲过std::async的启动策略,只有经由其启动的未推迟任务的共享状态的最后一个期值会保持阻塞直到该任务结束(析构函数对底层异步执行任务的线程实施了一次隐式join);其它所有期值的析构函数仅进行常规析构行为就结束了(如果被推迟任务的所有期值被析构其就不可能运行)。(C++11和C++14中情况一致)
常规析构行为即析构期值对象的成员,针对共享状态里的引用计数实施一次自减。共享状态由指涉到它的期值和被调方的
std::promise共同操纵,引用计数使得库能够知道何时可以析构共享状态。
条款39 考虑针对一次性事件通信使用以void为模板型别实参的期值
如果仅限于一次性通信,不需要条件变量,互斥量和标志位,使用std::promise型别对象和期值。
1 | |
条款40 对并发使用std:atomic,对特种内存使用volatile
std::atomic用于多线程访问的数据且不用互斥量,是撰写并发软件的工具。
volatile用于读写操作不可以被优化掉的内存,是在面对特种内存时使用的工具
1 | |
std::atomic型别对象的特点:
- 采用顺序一致性。有其它在代码重新排序方面更灵活的一致性模型,但难以维护。
- 所有成员函数都保证为原子的。不支持复制操作,硬件无法保证其为原子的。
常规内存:若多次写入之间没有读取操作,编译器可以消除多余的写入操作;若多次读取之间没有写入操作,编译器可以消除多余的读取操作。
特种内存:用于内存映射I/O的内存,与显示器、打印机等外部设备通信。因为通信会有读取和写入,所以要求编译器不对在此内存上的操作做任何优化。
std::atomic和volatile用于不同目的,所以它们可以一起使用:
1 | |
第8章 微调
条款41 针对可复制的形参,在移动成本低并且一定会被复制的前提下,考虑将其按值传递
1 | |
程序足迹(program footprint)通常是指目标代码经常性占用内存的尺寸(动态分配的内存,或是从外存加载到内存的部分往往不计在内)
使用以上三种方法进行以下实验:
1 | |
方法1:两个重载函数的实参均按引用传递,无成本,接收左值的重载函数内一次复制,接收右值的重载函数内一次移动。
方法2:实参按引用传递,无成本。函数内对于左值一次复制,对于右值一次移动。
方法3:实参按值传递,对于左值一次复制,对于右值一次移动。函数内一次移动。
综上,方法三总是多一次移动操作。当且仅当形参可复制、移动成本低、形参在函数内一定会被复制时考虑方法三。
一定会被复制指,形参传到函数后一定有复制操作,且该操作不会因为条件语句的判定不执行。
一定有复制操作时,传入左值,三种方法均有一次复制(方法1、2的复制发生在函数内,方法3的复制发生在传参时),方法3以额外多一次移动的代价克服了方法1增加程序足迹和方法2多个实例化的缺点。当移动成本低,这个交易就是划算的。
条款42 考虑置入而非插入
1 | |
下列情况置入比插入更高效:
- 欲添加的值是以构造而非赋值方式加入容器。
- 传递的实参型别与容器持有之物的型别不同。
- 容器不太可能由于出现重复情况而拒绝待添加的新值。
置入存在的问题:
直接完美转发构造所需的参数时,把对象创建推迟到在容器的内存中构造,若发生异常会导致资源泄漏。
越过了explicit对构造函数的限制:
1
2
3
4
5
6
7std::vector<std::regex> regexes;
// 接收const char *指针的std::regex构造函数声明为explicit,杜绝隐式转换
std::regex r = nullptr; // 不能编译
regexes.push_back(nullptr); // 不能编译
regexes.emplace_back(nullptr); // 能编译!使用直接初始化