Deep Learning with Pytorch
Eli Stevens,Luca Antiga ,Thomas Viehmann 著
牟大恩 译
封面
代码仓库
摘录整理。笔记目录不完全按照原书目录。
这本书的中文翻译有一些地方不通顺。稍修正。
第1部分 PyTorch核心
第1章
深度学习和PyTorch库简介
深度学习使用大量数据来近似输入和输出相距很远的复杂函数 ,如输入是图像,输出是对输入进行描述的一行文本;或输入是书面文字,输出是朗读该文字的自然语音。
深度学习是一个巨大的空间,本书只覆盖该空间的一小部分。具体来说,包括一些使用PyTorch进行较小范围的图像分类和分割的项目,通过一些示例处理二维和三维的图像数据集。
为什么用PyTorch?
Theano是最早的深度学习框架之一,目前它已经停止开发。
TensorFlow:
完全对Keras进行封装,将其提升为一流的API;
提供了一种立即执行的“急切模式(eager
mode)”,这种模式有点儿类似于PyTorch处理计算的方式;
TensorFlow 2.0默认采用急切模式。
JAX是谷歌的一个库,它是独立于TensorFlow开发的,作为一个与GPU、Autograd和JIT编译器具有对等功能的NumPy库,它已经开始获得关注。
PyTorch:
Caffe2完全并入PyTorch,作为其后端模块;
替换了从基于Lua的Torch项目重用的大多数低级别代码;
增加对开放式神经网络交换(Open Neural Network
Exchange,ONNX)的支持,这是一种与外部框架无关的模型描述和交换格式;
增加一种称为“TorchScript”的延迟执行的“图模型”运行环境;
发布了1.0版本;
取代CNTK和Chainer成为各自企业赞助商选择的框架。
随着TorchScript和eager模式的出现,PyTorch和TensorFlow的特征集开始趋同,尽管在这些特征的呈现和整体体验上仍然存在很大的差异。
事实上,由于性能原因,PyTorch大部分是用C++和CUDA编写的,CUDA是一种来自英伟达的类C++的语言,可以被编译并在GPU上以并行方式运行。有一些方法可以直接在C++环境中运行PyTorch,我们将在第15章中讨论这些方法。此功能的动机之一是为生产环境中部署模型提供可靠的策略。但是,大多数情况下我们都是使用Python来与PyTorch交互的,包括构建模型、训练模型以及使用训练过的模型解决实际问题等。
在PyTorch中,将运算从CPU转移到GPU不需要额外的函数调用。
第2章 预训练网络
这章主要下载使用了一些不同种类的预训练网络。
在深度学习中,在新数据上运行训练过的模型的过程被称为推理(inference) 。
1 2 3 4 from torchvision import modelsdir (models)
训练时候开启model.train(),启用 BatchNormalization 和
Dropout。测试(评估)时开启model.eval()。
第3章 从张量开始
张量可简单理解为多维数组。
Python列表或数字元组是在内存中单独分配的Python对象的集合,而PyTorch张量或NumPy数组通常是连续内存块的视图,这些内存块包含未装箱的数字类型,而不是Python对象。
tensor操作和numpy类似。
为了避免张量运算时粗心造成的对齐错误,可以对张量命名。
张量构造函数通过dtype参数指定包含在张量中的数字的数据类型:
torch.float32或torch.float:32位浮点数。
torch.float64或torch.double:64位双精度浮点数。
torch.float16或torch.half:16位半精度浮点数。
torch.int8:8位有符号整数。
torch.uint8:8位无符号整数。
torch.int16或torch.short:16位有符号整数。
torch.int32或torch.int:32位有符号整数。
torch.int64或torch.long:64位有符号整数。
torch.bool:布尔型。
张量的默认数据类型是32位浮点数。
我们在大部分时间使用32位浮点数和64位有符号整数,原因如下:
在神经网络中发生的计算通常是用32位浮点精度执行的。采用更高的精度,如64位,并不会提高模型精度,反而需要更多的内存和计算时间。16位半精度浮点数的数据类型在标准CPU中并不存在,而是由现代GPU提供的。如果需要的话,可以切换到半精度来减少神经网络占用的空间,这样做对精度的影响也很小。
张量可以作为其他张量的索引,在这种情况下,PyTorch期望索引张量为64位的整数。创建一个将整数作为参数的张量,例如使用torch.tensor([2,2]),默认会创建一个64位的整数张量。
张量操作分类:
创建操作——用于构造张量的函数,如ones()和from_numpy()。
索引、切片、连接、转换操作——用于改变张量的形状、步长或内容的函数,如transpose()。
数学操作——通过运算操作张量内容的函数。
逐点操作——通过对每个元素分别应用一个函数来得到一个新的张量,如abs()和cos()。
归约操作——通过迭代张量来计算聚合值的函数,如mean()、std()和norm()。
比较操作——在张量上计算数字谓词的函数,如equal()和max()。
频谱操作——在频域中进行变换和操作的函数。
其他操作——作用于向量的特定函数(如cross()),或对矩阵进行操作的函数(如trace())。
BLAS和LAPACK操作——符合基本线性代数子程序(Basic Linear Algebra
Subprogram,BLAS)规范的函数,用于标量、向量—向量、矩阵—向量和矩阵—矩阵操作。
随机采样——从概率分布中随机生成值的函数,如randn()和normal()。
序列化——保存和加载张量的函数,如load()和save()。
并行化——用于控制并行CPU执行的线程数的函数,如set_num_threads()。
张量是Storage实例的视图 。
一个张量的值在存储区中从最右的维度开始向前排列被定义为连续张量。在PyTorch中一些张量操作只对连续张量起作用,如view()方法。在这种情况下,PyTorch将抛出一个提供有用信息的异常,并要求我们显式地调用contiguous()方法。值得注意的是,如果张量已经是连续的,那么调用contiguous()方法不会产生任何操作,也不会影响性能。一个连续张量转置后不再是连续张量。
张量还有设备(device)的概念,即张量数据在计算机上的位置。
1 points_gpu = torch.tensor([[4.0 , 1.0 ], [5.0 , 3.0 ], [2.0 , 1.0 ]], device='cuda' )
pytorch可以与numpy互操作 :
1 2 3 points = torch.ones(3 , 4 )
PyTorch在内部使用pickle来序列化张量对象,并为存储添加专用的序列化代码。通过以下方法可以将张量points写到ourpoints.t文件中并读:
1 2 3 4 with open ('../data/p1ch3/ourpoints.t' ,'wb' ) as f:with open ('../data/p1ch3/ourpoints.t' ,'rb' ) as f:
第4章 使用张量表征真实数据
简单讲了下如何加载各种类型的数据。
第5章 学习的机制
手动求导并更新参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 import numpy as npimport torch2 , linewidth=75 )0.5 , 14.0 , 15.0 , 28.0 , 11.0 , 8.0 , 3.0 , -4.0 , 6.0 , 13.0 , 21.0 ]35.7 , 55.9 , 58.2 , 81.9 , 56.3 , 48.9 , 33.9 , 21.8 , 48.4 , 60.4 , 68.4 ]def model (t_u, w, b ):return w * t_u + bdef loss_fn (t_p, t_c ):2 return squared_diffs.mean()0.1 2.0 * delta)2.0 * delta)1e-2 def dloss_fn (t_p, t_c ):2 * (t_p - t_c) / t_p.size(0 ) return dsq_diffsdef dmodel_dw (t_u, w, b ):return t_udef dmodel_db (t_u, w, b ):return 1.0 def grad_fn (t_u, t_c, t_p, w, b ):return torch.stack([dloss_dw.sum (), dloss_db.sum ()])def training_loop (n_epochs, learning_rate, params, t_u, t_c ):for epoch in range (1 , n_epochs + 1 ):print ('Epoch %d, Loss %f' % (epoch, float (loss))) return params0.1 * t_u5000 , 1e-2 , 1.0 , 0.0 ]),
如果学习率过大,会导致参数更新过度、无法收敛;但如果学习率过小,则更新非常小,所以损失下降得非常慢,最终停滞不前。可以通过学习率自适应来解决这个问题,也就是说,根据更新的大小进行更改。
对于上例,权重的梯度大约是偏置梯度的50倍。这意味着权重和偏置存在于不同的比例空间中,在这种情况下,如果学习率足够大,能够有效更新其中一个参数,那么对于另一个参数来说,学习率就会变得不稳定,而一个只适合于另一个参数的学习率也不足以有意义地改变前者。可以采用归一化输入的方法使输入靠近输出,对于上例可以将t_u乘0.1。
自动求导手动更新参数
PyTorch张量可以记住它们自己从何而来,根据产生它们的操作和父张量,它们可以根据输入自动提供这些操作的导数链。这意味着我们不需要手动推导模型,给定一个前向表达式,无论嵌套方式如何,PyTorch都会自动提供 表达式相对其输入参数的梯度。
调用backward()将导致导数在叶节点上累加。再次调用backward()(就像在任何训练循环中一样),每个叶节点上的梯度将在上一次迭代中计算的梯度之上累加(求和),这会导致梯度计算不正确。为了防止这种情况发生,我们需要在每次迭代时明确地将梯度归零。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 params = torch.tensor([1.0 , 0.0 ], requires_grad=True )def training_loop (n_epochs, learning_rate, params, t_u, t_c ):for epoch in range (1 , n_epochs + 1 ):if params.grad is not None : with torch.no_grad(): if epoch % 500 == 0 :print ('Epoch %d, Loss %f' % (epoch, float (loss)))return params
自动求导并更新参数
使用优化器模块封装整个过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 params = torch.tensor([1.0 , 0.0 ], requires_grad=True )1e-2 def training_loop (n_epochs, optimizer, params, t_u, t_c ):for epoch in range (1 , n_epochs + 1 ):if epoch % 500 == 0 :print ('Epoch %d, Loss %f' % (epoch, float (loss)))return params
分割数据集
为了避免过拟合,可以单独分出一部分数据作为验证集。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 0 ]int (0.2 * n_samples)0.1 * train_t_u0.1 * val_t_udef training_loop (n_epochs, optimizer, params, train_t_u, val_t_u, train_t_c, val_t_c ):for epoch in range (1 , n_epochs + 1 ):with torch.no_grad():assert val_loss.requires_grad == False if epoch <= 3 or epoch % 500 == 0 :print (f"Epoch {epoch} , Training loss {train_loss.item():.4 f} ," f" Validation loss {val_loss.item():.4 f} " )return params
使用相关的set_grad_enabled(),还可以根据一个布尔表达式设定启用或禁用自动求导的条件。
第6章 使用神经网络拟合数据
神经元即线性变换+非线性激活函数。
激活函数两个作用:
允许输出函数在不同的值上有不同的斜率,这是线性函数无法做到的。
将前面的线性运算的输出集中到给定的范围内。
线性模型
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import torchimport torch.optim as optim1 ) 1 ) 1 , 1 ) 1e-2 )def training_loop (n_epochs, optimizer, model, loss_fn, t_u_train, t_u_val, t_c_train, t_c_val ):for epoch in range (1 , n_epochs + 1 ):if epoch == 1 or epoch % 1000 == 0 :print (f"Epoch {epoch} , Training loss {loss_train.item():.4 f} ," f" Validation loss {loss_val.item():.4 f} " )
可以用nn.MSELoss()代替前面自定义的loss_fn做损失函数入参。
神经网络
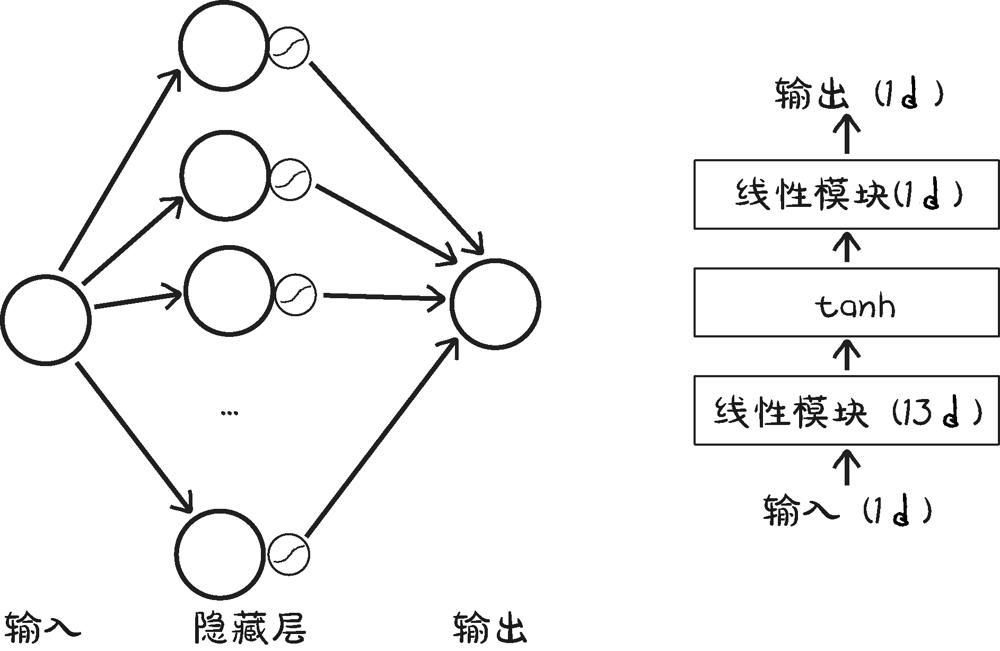
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 1 , 13 ), 13 , 1 )) ''' Sequential( (0): Linear(in_features=1, out_features=13, bias=True) (1): Tanh() (2): Linear(in_features=13, out_features=1, bias=True) ) ''' for name, param in seq_model.named_parameters():print (name, param.shape)''' 0.weight torch.Size([13, 1]) 0.bias torch.Size([13]) 2.weight torch.Size([1, 13]) 2.bias torch.Size([1]) ''' from collections import OrderedDict'hidden_linear' , nn.Linear(1 , 8 )),'hidden_activation' , nn.Tanh()),'output_linear' , nn.Linear(8 , 1 ))''' Sequential( (hidden_linear): Linear(in_features=1, out_features=8, bias=True) (hidden_activation): Tanh() (output_linear): Linear(in_features=8, out_features=1, bias=True) ) '''
下图是seq_model的结构:
第一个简单神经网络结构
第7章
区分鸟和飞机:从图像学习
读取微小图像数据集
CIFAR-10由60000张微小的(32像素×32像素)RGB图像组成,用一个整数对应10个级别中的1个:飞机(0)、汽车(1)、鸟(2)、猫(3)、鹿(4)、狗(5)、青蛙(6)、马(7)、船(8)和卡车(9)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 %matplotlib inlinefrom matplotlib import pyplot as pltimport numpy as npimport torchfrom torchvision import datasetsfrom torchvision import transforms2 , linewidth=75 )123 )'../data-unversioned/p1ch7/' True , download=False ,transform=transforms.ToTensor())for img_t, _ in tensor_cifar10], dim=3 )3 , -1 ).mean(dim=1 )3 , -1 ).std(dim=1 )True , download=False ,0.4915 , 0.4823 , 0.4468 ),0.2470 , 0.2435 , 0.2616 ))False , download=False ,0.4915 , 0.4823 , 0.4468 ),0.2470 , 0.2435 , 0.2616 ))
区分鸟和飞机
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 'airplane' , 'bird' ]0 : 0 , 2 : 1 }for img, label in cifar10 if label in [0 , 2 ]]for img, label in cifar10_valif label in [0 , 2 ]]import torchimport torch.nn as nnimport torch.optim as optim64 ,True )3072 , 512 ),512 , 2 ),1 ))1e-2 for epoch in range (n_epochs):for imgs, labels in train_loader:0 ]1 ))print ("Epoch: %d, Loss: %f" % (epoch, float (loss))) 64 ,False )0 0 with torch.no_grad():for imgs, labels in val_loader:0 ]1 ))max (outputs, dim=1 )0 ]int ((predicted == labels).sum ())print ("Accuracy: %f" , correct / total)0.794000
nn.LogSoftmax()和nn.NLLLoss()的组合相当于使用nn.CrossEntropyLoss()。交叉熵损失函数 是PyTorch的一个特性,实际上nn.NLLLoss()计算的是交叉熵,但将对数概率预测作为输入,其中nn.CrossEntropyLoss()用于计算分数(有时称为logits)。从技术上讲,nn.NLLLoss()计算的是把所有质量放在目标上的狄拉克分布和由对数概率输入给出的预测分布之间的交叉熵。
从神经网络中丢弃最后一个nn.LogSoftmax(),转而使用nn.CrossEntropyLoss()是很常见的。
第8章 使用卷积进行泛化
搭建卷积神经网络
仍然使用上一章加载好的数据。
torch.nn模块提供一维、二维、三维的卷积,其中nn.Conv1d用于时间序列,nn.Conv2d用于图像,nn.Conv3d用于体数据和视频。
卷积核各个方向的大小都相同是很常见的,因此PyTorch为此提供了一个快捷方式:每当为二维卷积指定kernel_size=3时,即3×3,Python是以tuple(3,3)提供的。对于三维卷积,核大小为3则表示是3×3×3。
给一个nn.Module的一个属性分配一个nn.Module实例,会自动将模块注册为子模块 。子模板必须是顶级属性,而不是隐藏在list或dict实例中,否则优化器将无法定位子模块以及它们的参数。对于子模块需要列表和字典的情况,PyTorch提供nn.ModuleList 和nn.ModuleDict 。
虽然在1.0版本中像tanh这样的通用科学函数在torch.nn.functional中依然存在,但不建议使用这些入口点,而是使用顶级torch命名空间的函数。像max_pool2d()这样的小众函数将保留在torch.nn.functional中。
nn.Module模块实现了一个将模型所有参数移动到GPU上的to() 方法,当你传递一个dtype参数时使用该方法还可以强制转换类型。对于Module.to来说,模块的实例会被修改,而Tensor.to会返回一个新的张量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 import torch.nn.functional as Fclass Net (nn.Module):def __init__ (self ):super ().__init__()3 , 16 , kernel_size=3 , padding=1 )16 , 8 , kernel_size=3 , padding=1 )8 * 8 * 8 , 32 ) 32 , 2 )def forward (self, x ):2 )2 )1 , 8 * 8 * 8 ) return outimport datetime def training_loop (n_epochs, optimizer, model, loss_fn, train_loader ):for epoch in range (1 , n_epochs + 1 ): 0.0 for imgs, labels in train_loader: if epoch == 1 or epoch % 10 == 0 :print ('{} Epoch {}, Training loss {}' .format (len (train_loader))) def validate (model, train_loader, val_loader ):for name, loader in [("train" , train_loader), ("val" , val_loader)]:0 0 with torch.no_grad(): for imgs, labels in loader:max (outputs, dim=1 ) 0 ] int ((predicted == labels).sum ()) print ("Accuracy {}: {:.2f}" .format (name , correct / total))
模型设计
训练模型涉及2个关键步骤:一是优化 ,当我们需要减少训练集上的损失时;二是泛化 ,当模型不仅要处理训练集,还要处理以前没有见过的数据,如验证集时。旨在简化这2个步骤的数学工具有时被归入正则化的标签之下。
在损失中添加一个正则化项
这是为了减小模型本身的权重,从而限制训练对它们增长的影响,对较大权重进行惩罚,使得损失更平滑,并且从拟合单个样本中获得的收益相对较少。
这类较流行的正则化项是L2正则化 ,它是模型中所有权重的平方和,而L1正则化是模型中所有权重的绝对值之和。它们都通过一个(小)因子进行缩放,这个因子是我们在训练前设置的超参数。
L2正则化也称为权重衰减 。叫这个名字的原因是考虑到SGD和反向传播,L2正则化对参数w_i的负梯度为−2
* lambda *
w_i,其中lambda是前面提到的超参数,在PyTorch中简称为权重衰减。因此,在损失函数中加入L2正则化,相当于在优化步骤中将每个权重按其当前值的比例递减(因此称为权重衰减)。注意,权重衰减适用于网络的所有参数,例如偏置。
在PyTorch中,我们可以通过在损失中添加一项来很容易地实现正则化。计算完损失后,无论损失函数是什么,我们都可以对模型的参数进行迭代,将它们各自的平方(对于L2)或绝对值(对于L1)相加,然后反向传播。
1 2 3 4 l2_lambda = 0.001 sum (p.pow (2.0 ).sum ()for p in model.parameters())
但是,PyTorch中的SGD优化器已经有一个weight_decay参数,该参数对应2
*lambda,它在前面描述的更新过程中直接执行权重衰减。它完全等价于在损失中加入L2范数,而不需要在损失中累加项,也不涉及自动求导。
不太依赖于单一输入:Dropout
将网络每轮训练迭代中的神经元随机部分清零。Dropout在每次迭代中有效地生成具有不同神经元拓扑的模型,使得模型中的神经元在过拟合过程中协调记忆过程的机会更少。另一种观点是,Dropout在整个网络中干扰了模型生成的特征,产生了一种接近于增强的效果。
1 self.conv1_dropout = nn.Dropout2d(p=0.4 )
在训练过程中Dropout通常是活跃的,而在生产过程中评估一个训练模型时,会绕过Dropout,或者等效地给其分配一个等于0的概率。这是通过Dropout模块的train属性来控制的。回想一下,PyTorch允许我们在任意nn.Model子类上通过调用model.train()或model.eval()来实现2种模式的切换。调用将自动复制到子模块上,这样如果其中有Dropout,它将在随后的前向和后向传递中表现出相应的行为。
保持激活检查:批量归一化
批量归一化使用在该中间位置收集的小批量样本的平均值和标准差来对中间输入进行移位和缩放。
1 self.conv1_batchnorm = nn.BatchNorm2d(num_features=n_chans1)
就像Dropout一样,批量归一化在训练和推理过程中需要表现出不同的行为。实际上,在推理时,我们希望避免特定输入的输出依赖于我们提供给模型的其他输入的统计数据的情况。因此,我们需要一种方法来继续归一化,但是这次要一次性固定所有的归一化参数。
在处理小批量时,除了估计当前小批量的平均值和标准差,PyTorch还更新代表整个数据集的平均值和标准差的运行估计数,作为近似值。这样,当用户指定model.eval(),并且模型包含批量归一化模块时,运行估计将被冻结并用于归一化。为了解冻运行估计并返回使用小批量统计信息,我们调用model.train(),就像我们对Dropout所做的那样。
第2部分
从现实世界的图像中学习:肺癌的早期检测
第9章 使用PyTorch来检测癌症
本书这一部分的项目将以人体躯干的三维CT扫描作为输入,并输出疑似恶性肿瘤的位置(如果存在的话)。
至少8GB内存的GPU,在CPU上尝试训练我们将建立的模型可能需要几个星期。还需要至少220
GB的空闲磁盘空间来存储原始训练数据、缓存数据和训练过的模型。
CT扫描本质上是三维X射线,以单通道数据的三维数组表示。
CT扫描的每一个体素都有一个数字值,大致对应其内部物质的平均质量密度。这些数据的大多数可视化显示高密度的骨骼和金属植入物是白色的,低密度的空气和肺组织是黑色的,脂肪和组织是灰色的。同样,这看起来有点儿像X射线,但有一些关键的区别。CT扫描和X射线的主要区别在于,X射线是在二维平面上的三维强度投影,在本例中是组织和骨密度,而CT扫描保留了数据的第三维。
CT扫描实际上测量的是放射性密度,它是被检查材料的质量密度和原子序数的函数。
完整的端到端解决方案
步骤1:加载原始CT扫描数据,并将其转换为可以使用PyTorch处理的数据格式。将原始数据转换为可以使用PyTorch处理的格式是你面对任何项目要执行的第1步。对于二维图像数据,该过程稍微简单,而对于非图像数据则更简单。
步骤2:使用PyTorch实现一种称为分割的技术来识别肺部潜在肿瘤的体素,这大致类似于生成一个用于输入分类器中的区域的热力图。这将使我们能够把注意力集中在肺部潜在的肿瘤上,而忽略大量无关的解剖结构,例如,一个人的胃里不可能有肺癌细胞。一般来说,在学习过程中,能够专注于一个单一的小任务是最好的。根据经验,在某些情况下,越复杂的模型结构可以产生越高级的结果,例如,我们在第2章中看到的GAN游戏。但是从头开始设计它们首先需要广泛掌握基本构建块,就像在跑之前要先学会走一样。
步骤3:将所关注的体素分组成块,即候选结节。在本项目,我们将在热力图上找到每个热点的粗略中心。每个结节都可以通过其中心点的索引、行和列来定位。我们这样做是为了向最终分类器呈现一个简单的、有约束的问题。对体素进行分组不会直接涉及PyTorch,这就是为什么我们将其分为一个单独的步骤。通常,当使用多步骤解决方案时,在较大的、以深度学习为动力的项目之间会有非深度学习黏合的步骤。
步骤4:利用三维卷积将候选结节分为实际结节或非结节。这在概念上类似于我们在第8章中提到的二维卷积。从候选结构决定肿瘤性质的特征对于所讨论的肿瘤来说是局部的,因此这种方法应该在限制输入数据大小和排除相关信息之间做出合理的平衡。做出这样的范围限制决策可以约束每个单独的任务,这有助于限制故障诊断时要检查的内容的数量。
步骤5:使用单个结节的联合分类来诊断患者。与上一步中的结节分类类似,我们将尝试仅根据影像数据判断结节是良性还是恶性。我们将对每个肿瘤的恶性程度进行最简单的预测,因为只要有一个肿瘤是恶性的,病人就会患上癌症。其他项目可能希望使用不同的方法将每个实例的预测聚合到一个文件中,在这里,我们会问:“有什么可疑之处吗?”所以最大值很适合用于聚合。如果我们要寻找定量信息,如“A型组织和B型组织的比例”,我们可能会选择一个合适的平均值。
我们将用于训练的数据为步骤3和步骤4提供了人工标注的输出,这使得我们可以将步骤2和步骤3看作与步骤4相对独立的项目。人体专家已经为结节的位置标注了数据,因此我们可以按照自己喜欢的顺序处理步骤2、步骤3或步骤4。
第10章
将数据源组合成统一的数据集
我们的CT数据来自2个文件:一个.mhd文件包含元数据头信息,另一个.raw文件包含组成三维数组的原始数据。我们所讨论的CT扫描的每个文件的名称都以一个称为系列UID的唯一标识符开始,该名称依据医学中的数字成像和通信(DICOM)命名法。例如,对于uid1.2.3系列,有2个文件——1.2.3.mhd和1.2.3.raw。Ct类将使用上述2个文件生成三维数组,并进行矩阵转换,将病人坐标系(我们将在10.6节中详细讨论)转换为数组所需的索引、行和列坐标。这些坐标在图中显示为(I,R,C),在代码中用_irc变量后缀表示。
candidates.csv 文件包含所有可能看起来像结节的肿块信息,无论这些肿块是恶性肿瘤、良性肿瘤还是其他。其中包含了CT序列、候选结节的位置,以及一个标示(指示该候选者是否真的是结节):
seriesuid,coordX,coordY,coordZ,class
class是一个布尔值:0表示非结节的候选者,1表示结节的候选者,可能是恶性的或良性的。
annotations.csv 文件包含一些已标记为实际结节的候选者的信息:
seriesuid,coordX,coordY,coordZ,diameter_mm
annotations.csv文件中提供的位置信息并不总是与candidates.csv中的坐标精确对齐。
每个结节的信息:结节状态(用于训练模型进行分类)、直径(有助于在训练中获得良好的传播,因为大结节和小结节的特征不同)、序列(定位正确的CT扫描)和候选中心(在更大的CT扫描中寻找候选者)。
1 2 3 4 5 6 from collections import namedtuple'CandidateInfoTuple' ,'isNodule_bool, diameter_mm, series_uid, center_xyz' ,
CT扫描的原始文件格式是DICOM,UNA已经将我们在本章中使用的数据转换为MetaIO格式,可以将数据文件的格式视为黑盒,并使用SimpleITK将它们加载到更熟悉的NumPy数组中。
1 2 3 4 5 6 7 8 9 10 import SimpleITK as sitkclass Ct :def __init__ (self, series_uid ):'data-unversioned/part2/luna/subset*/{}.mhd' .format (series_uid) 0 ]
我们使用创建CT扫描时分配的序列UID(series_uid)来识别特定的CT扫描。DICOM大量使用UID来表示单个DICOM文件、文件组、疗程等。UID在概念上与UUID相似,但是它们的创建过程不同,格式也不同。出于我们的目的,我们可以将它们视为不透明的ASCII字符串,作为引用各种CT扫描的唯一键。在正式场合,只有字符0~9和句号(.)是DICOM
UID的有效字符。
10个子集每个有大约90个CT扫描,总共888个。每个CT扫描表示为2个文件:一个带有.mhd扩展名,一个带有.raw扩展名。然而,在多个文件之间分割的数据隐藏在sitk例程后面,这不是我们需要直接关注的。
亨氏单位
CT扫描以亨氏(Hounsfield
Unit,缩写为HU)单位表达,它是一个奇特的单位。空气是−1000
HU(接近于0g/cm3,其中g/cm3表示克/立方厘米),水是0 HU(1
g/cm3),骨骼至少是+1000 HU(2~3
g/cm3)。HU值通常存储在磁盘上,作为有符号的12位整数插入16位整数中,这非常符合CT扫描仪所能提供的精度水平。一些CT扫描仪使用对应负密度的HU值来表示CT扫描仪视角之外的体素。出于我们的目的,病人身体之外的所有东西都应该是空气,因此我们通过将值的下限设置为−1000
HU来丢弃该视角信息。同样,骨骼、金属植入物等的精确密度与我们的用例无关,因此我们将密度限制在大约2
g/cm3(1000 HU),尽管这种做法在生物学上并不准确。
第11章
训练分类模型以检测可疑肿瘤
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 class LunaModel (nn.Module):def __init__ (self, in_channels=1 , conv_channels=8 ):super ().__init__()1 )2 )2 , conv_channels * 4 )4 , conv_channels * 8 )1152 , 2 )1 )def _init_weights (self ):for m in self.modules():if type (m) in {0 , mode='fan_out' , nonlinearity='relu' ,if m.bias is not None :1 / math.sqrt(fan_out)def forward (self, input_batch ):0 ),1 ,return linear_output, self.head_softmax(linear_output)class LunaBlock (nn.Module):def __init__ (self, in_channels, conv_channels ):super ().__init__()3 , padding=1 , bias=True ,True )3 , padding=1 , bias=True ,True )2 , 2 )def forward (self, input_batch ):return self.maxpool(block_out)
第12章
通过指标和数据增强来提升训练
定义和计算精度、召回率、真/假阳性或阴性。
使用F1分数和其他质量指标。
平衡和增强数据以减少过拟合。
使用TensorBoard绘制质量指标。
第13章
利用分割法寻找可疑结节
用像素模型分割数据。
使用U-Net进行分割。
理解使用骰子损失的掩码预测。
评估分割模型的性能。
第14章
端到端的结节分析及下一步的方向
连接分割和分类模型。
为新任务微调网络。
向TensorBoard添加直方图和其他指标类型。
从过拟合到泛化。
第3部分 部署
第15章 部署到生产环境
15.1 PyTorch模型的服务
使用flask在服务器端接受请求以运行模型返回结果。
使用Sanic异步并行处理批处理请求。
15.2 导出模型
ONNX
从某种意义上说,深度学习模型是一个具有非常特定的指令集的程序,由矩阵乘法、卷积、ReLU、tanh等精细运算组成。因此,如果我们可以序列化计算,我们可以在另一个理解其低级操作的运行时中重新执行它。ONNX是描述这些操作及其参数的标准格式。
大多数现代深度学习框架都支持将它们的计算序列化到ONNX,其中一些框架可以加载ONNX文件并执行它(尽管PyTorch不是这样)。一些低占用(“边缘”)设备接受将ONNX文件作为输入,并为特定设备生成低级指令。一些云计算提供商现在允许上传ONNX文件,并通过REST端点查看它公开的内容。
TorchScript
当互操作性不是关键,但我们需要避开Python
GIL或以其他方式导出网络时,我们可以使用PyTorch自己的表示——TorchScript图。
制作TorchScript模型最简单的一种方法是跟踪它。这看起来很像ONNX导出。这并不奇怪,因为跟踪也是ONNX模型在底层使用的方法。这里我们只是使用torch.jit.trace()函数将虚拟输入输入模型中。
15.3 与PyTorch JIT编译器交互
PyTorch JIT编译器在PyTorch
1.0中首次亮相,它是PyTorch许多创新的核心,其中最重要的是提供了一组丰富的部署选项。
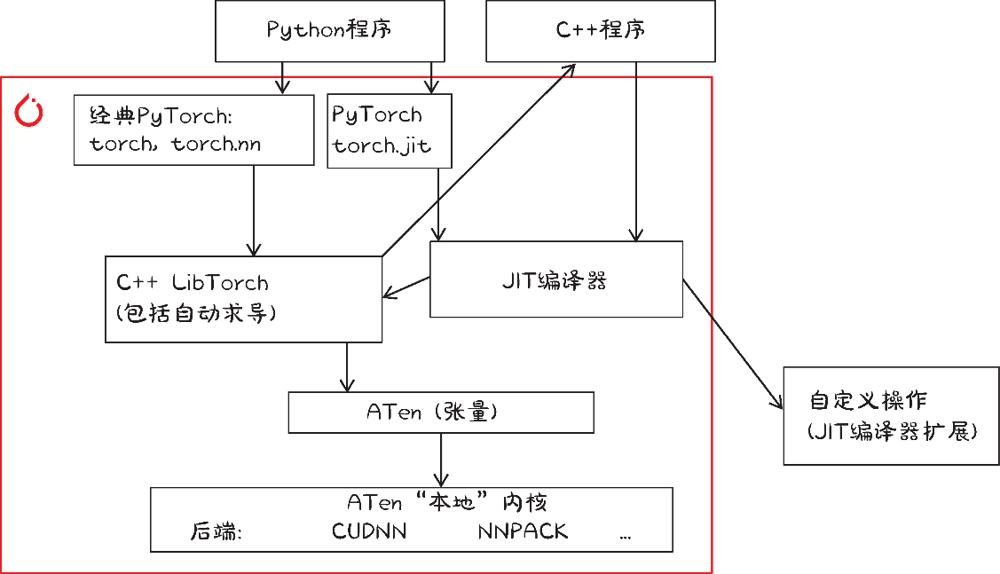
4种调用PyTorch函数的方法
15.4 LibTorch:C++中的PyTorch
放弃Python而直接使用C++ API。
15.5 部署到移动设备
PyTorch的C++部分,即LibTorch,可以在Android上编译,我们可以使用Android
Java本地接口(Java Native
Interface,JNI)从Java编写的应用程序中访问它。但我们实际上只需要PyTorch中的几个函数,加载JITed模型,将输入转换为张量和IValue,在模型中运行它们,然后返回结果。为了省去使用JNI的麻烦,PyTorch开发人员将这些函数封装到一个名为PyTorch
Mobile的小型库中。
15.6
新兴技术:PyTorch模型的企业服务
略。