Lumen和Nanite学习
Lumen & Nanite in UE5
Lumen Livestream
Lumen | Inside Unreal - YouTube / 2021年6月11日
开场之前的5分钟的鸡蛋不能飞动画片确实没有看懂……
标题自行组织,与视频章节不一一对应。

Goals
以次世代主机为目标,扩展到高端PC。
全动态GI和完美反射。
无缝同时支持:
大型开放世界
室内GI
室内的光照往往只来自一小块区域,所以非常困难。
Features
没有烘焙光照,ms级GI。

带阴影的天空光照,让室内比室外更暗,只需在场景中放置一个可移动的天空光照。

自发光。不可以替换光源,需要保持其subtle。

与GI集成的反射。如果材质足够光滑,它会追踪额外的光线。这很重要否则除了太阳光照射的地方一切都是黑的。

反射只影响屏幕上的内容,没有caustics。
焦散,比如太阳照进窗户,从地板高光反射到天花板形成图案。计算机图形学的定义是:焦散是任何从光源到高光(反射或折射)、到漫反射表面、再到眼睛(或摄影机)的光照贡献。
Daniel Wright:如果有焦散,那将是在UE6。
Lumen支持clear coat,实际上有两层反射。比如汽车油漆。

支持半透明和体积雾的GI和带阴影天空光照,但是质量很低。这很难解决,因为每个像素都有任意数量的层。

Settings
创建项目时,Lumen是默认开启的。
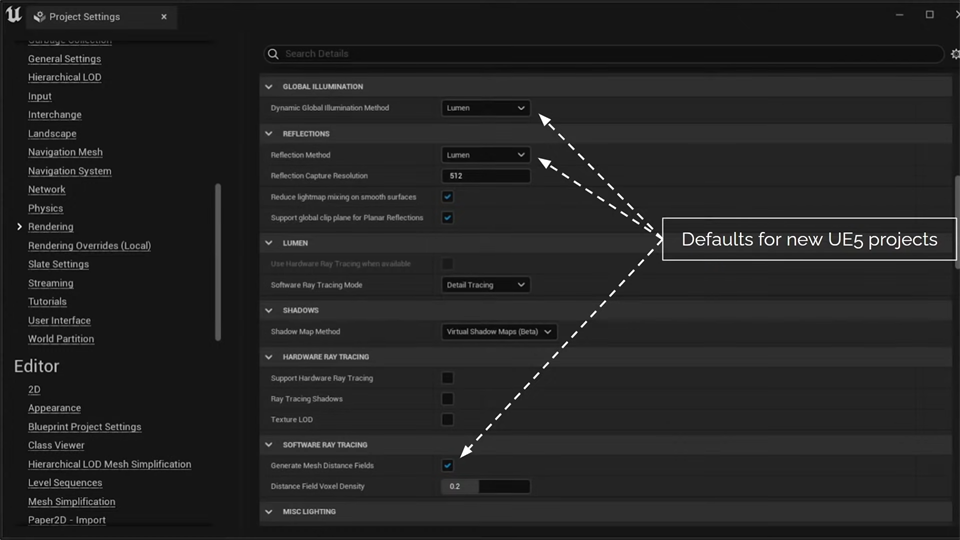
要获得顶级光照,必须打开硬光追。LUMEN->Use Hardware Ray Tracing when available && HADRWARE RAY TRACING -> Support Hardware Ray Tracing。
可以在Post Process Volume中重写GI和反射的方法,用作QA(质量保证)。还可以对场景的不同地方提高Lumen的质量,但这会带来更多消耗。
Lumen可设置的不多,主要有光照属性、材质属性、曝光。
How Lumen Works
从高级别看,Lumen默认使用软光追,这专为UE5开发。
- 首先利用深度缓存追踪(屏幕追踪)。
- 如果光线被挡住或者射出屏幕外,在compute shader里使用SDF追踪。首先追踪单个物体的距离场,这个代价比较高,因此当光线变得更远时只追踪全局距离场。
- 当光线击中SDF,通过surface cache获得击中点的光照。
Hybrid tracing pipeline
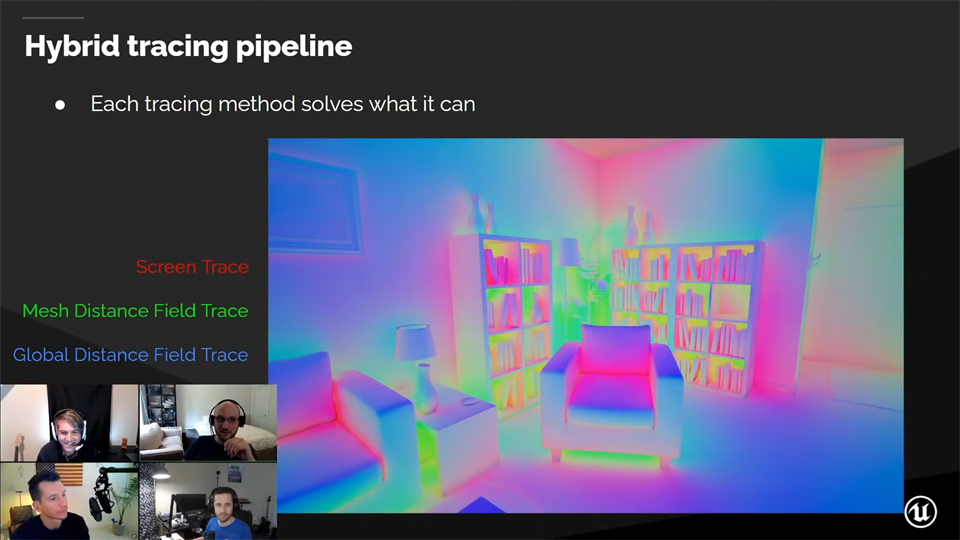
每个像素的GI都是通过不同类型追踪组合而成。
Mesh Distance Fields
相比UE4,UE5的距离场全部重写了,它们是稀疏的,并且生成距离场的mipmap,只需要根据距离选择版本。默认体素密度提高2倍(相当于数据量提高8倍),每个网格的默认分辨率提高4倍,净内存消耗降低一半。建立网格距离场速度增加10倍。在简单光照下视觉效果更好。
Surface Cache
从不同方向捕获网格并将它们存储到图集中,并整理出所有材料属性。在场景中漫游时,将会重新捕获。

但是,它仅当网格有简单interiors时有效。比如复杂的墙面必需由单独的网格组成。
LumenScene

如果LumenScene中的场景与屏幕上的不匹配,GI中就会出现view-dependent artifacts。
优化方法:
- 将所有网格距离场合并为全局距离场。
- 将Surface Cache合并到Voxel Lighting
LUMEN->Software Ray Tracing Mode:
Detail Tracing - 默认在两米内追踪网格距离场。
Global Tracing - 跳过网格距离场全局追踪。
Limitations
软光追的限制:
只支持Static Mesh和Instanced Static Mesh
Landscape支持将在5.0版本发布
世界位置偏移会导致artifacts,因为无法在距离场中复制每个顶点的变形。
更多的可以直接看Lumen文档,很详细
软光追可以在任何DX11以上硬件上运行,但只支持有限的几何类型。
Hardware Ray Tracing
在PC上,只有在D3D12下运行时有效。
显卡需要是Nvidia RTX2000以上或AMD RX6000以上。
只支持用于反射和部分final gather。
Nanite可以实现几个数量级的更高详细几何形状,但这依赖于光栅化器特定技术和解压缩顶点格式,这与硬光追的API不兼容。因此不能对原始的Nanite三角形进行追踪,Nanite提供了一个简化的代理几何以供追踪。
也可以用屏幕追踪解决这种不匹配,因为屏幕上是全分辨率的实际的Nanite光栅化几何。当这被阻塞时将使用代理几何。可以在Nanite里设置。
在大多数情况下可以只使用代理几何,除了汽车之类的。汽车表面非常薄,代理几何做的简化会过于简单。
Proxy Triangle Percent默认情况下仅为1%,设置为2%~4%即可修复所有错误。
对于Skinned Mesh这样的动态几何,每一帧都要重建光线追踪加速结构BVH,耗费非常大。
小心!对于硬光追kitbashing耗费很大,因为网格重叠。
硬光追比软光追慢50%,但是更准确。
Final Gather
指最终到屏幕上的像素的处理过程。
光线追踪很慢,只能承担每个像素大约半条光线的成本。但是对于室内场景,可接受的图像质量需要每个像素200条光线的成本!
两种方法解决:
- Irradiance Fields
- 需要艺术家手动设置探针
- Screen Space Denoiser
- 输入仅来自屏幕,质量有限
Lumen使用Screen Space Radiance Caching。仅对很小的一组位置追踪然后插值(与Nanite表面细节法线结合)。

还需要World Space Radiance Caching来实现稳定的远距离光照。这通过放置少得多的探针来实现。

Reflections
对于粗糙度<0.4的,追踪额外光线。 >0.4的,重用final gather追踪。
默认情况下反射使用Surface Cache,即使打开硬光追。
可以在设置中把REFLECTIONS -> Lumen Reflections- >Quality调整到4.0,来使Lumen真正评估击中点的光照。但是,天空和多次弹射仍然使用Surface Cache。
对比:

Best Practice
Emissive
不能使用Lumen+Emissive meshed代替光源。
Emissive越小越亮越嘈杂,最好是large dim或small dim+光源。
BaseColor
对GI影响很大。
Dark and noisy BaseColor = poor GI
官方的 Lumen in the Land of Nanite 就提升了BaseColor。
Indirect Lighting Intensity
非间接光照的强度,可以直接设置。
Surface Cache
记得关注Lumen Scene视图并调整使其与主场景同步。之前提过,有复杂interiors的网格使其无效。
这确实麻烦,但比创建lightmap UVs并等待10分钟的构建要好。
Platforms
- 只支持下一代主机和高端PC。
- 不支持移动端。
- 不支持VR。除了VR对分辨率要求很高之外,Lumen 需要 deferred shading pipeline,但是VR项目大多依赖forward shading pipeline来降低开销和MSAA。
- 硬光追有额外的要求-见文档。
Performance
很大程度上依赖Temporal Super Resolution。
1080p internal -> 4k output
主机默认上采样,但PC不是,如果用带4k屏的PC,可以自己设置一下Screen Percentage。
History
Daniel Wright (Engineering Fellow, Graphics - EpicShaders)等一共3个人从19年3月开始工作了约两年完成lumen。
Daniel :在过去12个月硬光追甚至还不存在,因此这段时间为这做了很多改进。(这个视频的时间是21年6月份)
Lumen Content Examples
演示了Lumen in the Land of Nanite,LakeHouse。
对于比较薄的物体和镜面反射,只有硬光追work。
QA
仅记录部分。
Q: UE5支持三个以上光照通道吗?
A: 0个。光追时不记录光线来自哪个光源,这样成本太高。
Q: Lumen用于基于光照的粒子效果,自发光的粒子效果如何影响场景?
A: 不能很好工作。小亮度的组合不适用于Lumen emissive。快速移动的光比如枪口闪光需要将间接光照强度设为0,这样就看不到延迟了。
Q: 能不能将特定的网格体排除在Lumen的影响之外,举个例子,假设有一个科幻主题的走廊,里面装饰着很多自发光灯管,那么在当前或者未来有没有可能将这些自发光物体排除在Lumen的影响之外?
A: 如果你想使用Lumen构建一个有很多小型自发光材质的科幻场景,那么就会产生很多噪点,目前我们还没有办法控制这种影响,这是因为屏幕空间追踪的原因。屏幕空间追踪会命中屏幕上的所有表面,然后捕捉相应的颜色,如果想单独呈现一个可以将自发光物体隐藏起来的Lumen视图屏幕追踪是不支持的,所以这个方面我们还要再研究一下。
Q: 有没有可能让Lumen在影片渲染队列等工具上加快计算和收敛?因为它会逐帧发生。这是有可能的吗?
A: 这是我们必须要做的一件事,尤其是针对摄像机切换。因为Lumen的目标是实时,它需要多个帧来收敛,如果有摄像机切换就会产生噪点图像,几帧后图像又会改变,呈现出弹出的切换效果。所以我们需要预热为早期的帧提供更多的预算,让渲染更顺畅,让Lumen与过场动画配合得更好。如果是做渲染,那么我们就要使用更高的质量设置,因为性能将不再是一个问题,但是现在我们还没有实现。
Q: 是否会将Lumen GI转换成光照贴图,加快烘焙速度?
A: 不会。我们其实可以通过GPU lightmass获得非常好的光照贴图预览。Lumen是在屏幕上工作的,不经过光照贴图纹理,因此不适合预览光照贴图。因为它不能像光照贴图UV一样准确呈现光照贴图失真,又比如贴图分辨率过低、网格体上的UV丢失、网格体重叠等等。你可能想在预览中看到这些瑕疵,然后在开始长时间的构建之前修复好。但是Lumen无法显示这些瑕疵,GPU Lightmass预览可以。
Q: 网格体距离场在UE4中具有非均匀缩放的限制,现在还有吗?
A: 大多数情况下,没有非均匀缩放基本上已经不成问题。如果缩放得过大,比如说一个方向上的缩放是另一个方向上的4倍,这个时候可能会出现失真。
Q: 次表面或者半透明材质是怎样的?之前我有看到过你展示的玻璃,但是次表面呢?
A: 之后我们打算为次表面阴影模型提供支持,但是现在还没有完成。我们还计划通过Lumen的追踪功能支持光的散射,但是现在还不行。
Q: Lumen与烘焙光照结合使用?比如Lumen用于某些场景,烘焙光照用于其他场景。
A: 我们研究过烘焙室内光照的可行性,尤其是室内有很多光源而且需要提供高品质光照的室内场景,然后在室外利用Lumen实现动态光照。最终的结论是两者结合并不是一个很好的解决方案。因为Lumen的性能开销很大程度上依赖于屏幕,取决于屏幕分辨率,即使是在烘焙光照的区域 Lumen也会产生开销。我们的目的是在两者之间实现无缝过渡,因此我们最终决定不提供这样的支持,但是我们希望光照贴图GI可以为Lumen反射提供支持,就像今天的光线追踪反射一样。这是未来我们希望实现的目标。
Q: 能不能举个例子展示一下水体效果?我很想知道Lumen对水体的作用。
A: Lumen反射在单层水面上不起作用,就是你给水体选择的阴影模型。但是我们正在努力实现这项功能,我不确定会不会在5.0版本推出。
Lumen / SIGGRAPH course
2022 SIGGRAPH course 里的一节,Lumen: Real-time Global Illumination in Unreal Engine 5

ppt首页作者依然是官方直播那三个人。官方直播是Daniel主讲,主持人主持,另外两个嘉宾交互。这个是这三个人依次讲,Daniel介绍整个架构和屏幕追踪部分,Krzysztof讲软光追和屏幕缓存部分,Patrick讲硬光追部分。
内容相比官方直播增加了Lumen开发的思路和实现细节。
基础问题
#1 如何追踪光线?
硬光追受硬件设备限制;使用二级加速结构处理具有大量重叠网格的场景会很慢。因此开发解决这些问题的软光追。
尝试使用一堆2D正交相机捕捉表面,得到卡片,对卡片高度场光追,击中时对卡片照明采样。因为这是2D表面表示,与体素这种3D表示相比空间分辨率高,并且和视差遮挡映射(POM)一样利用高度场实现了快速软光追。但不可能用高度场覆盖整个场景,缺失的区域会漏光。
使用符号距离场(SDF)可以覆盖所有区域,并且通过球体追踪实现快速软光追。但是求交只能得到击中位置和法线,得不到材质属性或光照。
结合以上两种方法,根据卡片在SDF光追击中的地方进行光照插值,没有覆盖到的区域仅会损失能量,而不会漏光。
卡片(cards)即为表面缓存(Surface Cache)。优点如下:
- 在间接光线之间共享材质评估和照片。
- 跨帧缓存,直接控制更新成本。
- 为硬光追提供快速路径。
Lumen光追管线:
屏幕追踪 -> 硬光追 / 软光追(取决于配置)-> 表面缓存(击中) / 天空光(未击中)(P56)
#2 整个间接照明路径如何解决?
对于室内场景需要多次反弹的漫反射,并且需要在反射中看到全局照明。
第一次反弹是最重要的,把他分开并用专门的技术解决,对于漫反射这称为最终聚集,对于镜面反射这就是反射去噪。
↻表面缓存 -> 最终聚集(Final Gather) / 反射 -> 图片 (P11)
第一次反弹之后的任何反弹都通过表面缓存使用反馈解决。表面缓存从自身读取数据,我们从它收集数据,每次更新传播另一次间接光照的反弹。
#3 如何解决光传输中的噪声?
甚至无法承担每个像素一条光线的开支。
最终聚集技术:
- 自适应下采样
- 时空重用
- Product 重要性采样
最终聚集域:
不透明 - 屏幕空间 - 连续2.5d
透明和雾 - 相机对齐体积- 连续3d
表面缓存 - 纹理空间- 不连续2d
反射降噪:
- 时空重用
- 双边滤波
- 重用漫反射光线
大纲
- 光追管线
- 屏幕追踪
- 软光追
- 表面缓存
- 硬光追
- 追踪表现
- 最终聚集
- 反射
- 表现和可扩展性
光追管线
混合光追管线:屏幕追踪 -> 硬光追 / 软光追(取决于配置)-> 天空光(未击中)。
每种追踪方法从上一个方法停止的地方开始。
屏幕追踪
屏幕追踪优点:
- 光追场景和GBuffer不匹配,需要其解决
- 处理主要追踪方法未表示的几何类型,比如蒙皮网格
- 适用于任何比例,对细节GI有效
屏幕追踪使用线性步长会跳过薄物体。因此,使用HZB(Hierarchical Z Buffer)遍历,具体是Closet HZB mips无堆栈遍历。
屏幕追踪结束后,一些光线已经解决,移除空的追踪通道,进行压缩后再运行下一个追踪路径。
软光追
无法代替硬光追,但是可以做出不同的权衡。
基元(Primitive)
- 网格距离场
- 景观高度场
基元存储在两层结构中,底层是基元,顶层是扁平的实例描述符数组。
在网格导入期间生成网格距离场(性能:~0.6ms建造1.5M三角形网格)。使用Embree点查询找到最近三角形距离,从每个体素投射64条光线计算命中数来决定是否在几何体内部。在mip映射的虚拟体积纹理中存储一个窄带距离场,以节省内存。
每一帧调度一个着色器遍历所有实例,着色器由每个距离场到摄像机的距离计算mip级别。然后将请求下载到CPU。
距离场存储在一个固定大小的池中,由简单的线性分配器管理。
使用mipmap加速光线行进,步数限制为64。击中后用6个采样点的中心差分计算几何法线,用来在表面缓存中采样材质和光照。
景观被分成多个组件,每个组件的表面缓存有一个高度场。顶层处理与网格距离场相同,底层对高度场进行光线行进,尝试找到零交叉点。找到两个样本后,一个在高度场上方,一个在高度场下方,在它们之间进行线性插值找到最终击中点。在击中点根据不透明度决定是接受还是继续追踪。接受后评估表面缓存计算光线辐射率。
Mesh SDF -> Global SDF
BVH和网格等加速结构对于长不连贯光线来说太慢了,需要检查每一个重叠的网格。仅在追踪短光线时使用这个办法。
只对光线的第一段(2m)进行精确的场景表示,之后切换到粗糙的场景表示。在运行时合并实例,全局距离场将所有网格距离场和高度场合并为一组以相机为中心的裁剪图。这消耗巨大,使用缓存加速场景修改时所做的更新。
追踪全局距离场时,从最小的开始遍历clipmaps,对每一个进行光线行进,直到击中。
SDF追踪存在的问题和解决方法
- 许多网格没有关闭,会产生负区域。在4个体素后插入负区域。
- 受分辨率限制,小于两个体素之间距离的薄网格距离场无法正确计算。在运行时扩展距离场,为避免扩展导致的过度遮挡,需要使用表面偏差逃离表面,打破接触阴影(P48-P54)。
表面缓存
SDF没有顶点属性,只有位置、法线和网格实例。需要使用表面缓存缓存材质、光照、多次反弹。
材质
对于Lumen,使用投影卡片(cards)——均匀的矩形面元簇。卡片是基于投影的,不需要用顶点属性评估。可以在运行时捕获和缩放,无需烘焙。
在网格导入期间进行预计算(性能:~0.2ms to build a large 1.5M tri mesh)。所有卡片都是轴对齐的,简化生成和查找。
将输入的网格的三角形数据体素化为轴对齐面元,对面元进行聚类,聚类转化为卡片。如果网格太难展开或太小,回退到像投影一样的6边立方体贴图。
使用网格和材质数据填充卡片,之后将其投影到表面上。
光照
使用缓存,每帧仅更新表面缓存的一个子集。对于全局辐射场使用体素照明。
优点和缺点
快速评估光照和材质,同时对软光追和硬光追有用。高质量的多次反弹。
体素照明太粗糙了。表面层数量有限制。
硬光追
硬光追在Lumen中的初始部署是为了反射。可以直接将UE4的光追反射模型集成进来,但是它缺少正确的镜面发射遮挡,造成未加阴影的天空光。
使用表面缓存管线,用一个最近命中着色器替换一组依赖于材质的最近命中着色器,这个着色器只获取提取几何法线和表面缓存参数化所需的数据。然后光线着色器将光照应用为法线加权表面缓存评估。
UE4需要64字节来存储用于动态光照的类似GBuffer参数(BaseColor、Normal、Roughness、Opacity、Specular等),而表面缓存管道只需要20个字节来存储查询表面缓存照明所需的参数。
表面缓存管线简化了着色器绑定表的构造,绑定循环不再需要依赖于材质的资源。(P97)
对于以下3个部分:
- Albedo
- Direct Lighting
- Indirect Lighting
在用于速度的Surface Cache光照配置中,全部使用表面缓存。
在用于质量的Hit Lighting光照配置中,前两者动态评估,后者使用表面缓存。(仅反射使用)
因为强制BVH中的所有对象不透明以避免使用任意命中着色器,对于部分不透明的几何体,需要采用额外的策略。对于半透明材料,完全跳过这些网格,对于alpha蒙版材质,评估表面缓存不透明度并跳过不透明度低于50%的网格。由于省略任意命中着色器,因此每当遇到部分不透明的表面时,必须迭代遍历光线生成着色器中的场景。此迭代计数由MaxTranslucentSkipCount着色器参数控制。
DXR内联光追。(P105)
通过矩阵觉醒讲解了硬光追过程中遇到的问题和解决方法,特别是介绍了从高质量近场几何级联到低质量远场几何的几何表示。(P106-P130)
管线结构:
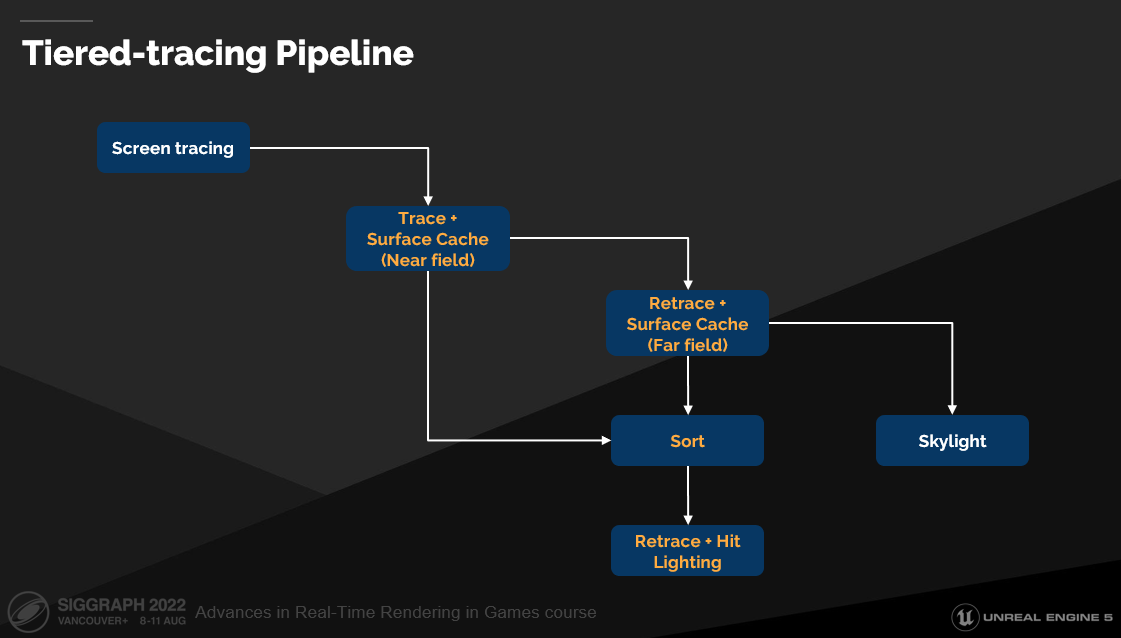
追踪表现
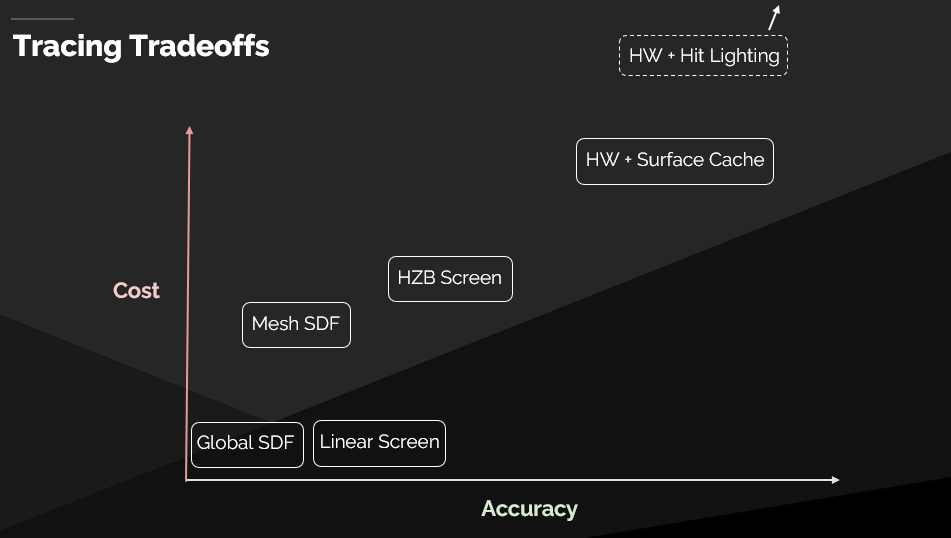
软光追
- 快但质量很低
- 适合高度重叠的网格(kitbashing)
硬光追
- 高质量但慢
- 适合镜面反射和蒙皮网格
最终聚集
预过滤圆锥追踪高效地解决了噪声,但是无法完全解决漏光或者过度遮挡,永远无法解决远处小窗户的照明问题,只适用于软光追。
使用蒙特卡洛积分将质量提升至最高,将噪声问题交给最终聚集解决。
屏幕空间辐射缓存
实际上是自适应下采样。从放置在屏幕像素上的探针开始追踪,将它们的辐射内插到同一平面内的任何其他像素。
在帧上抖动探针的放置网格,随时间累积以获得良好的覆盖。
不透明最终聚集
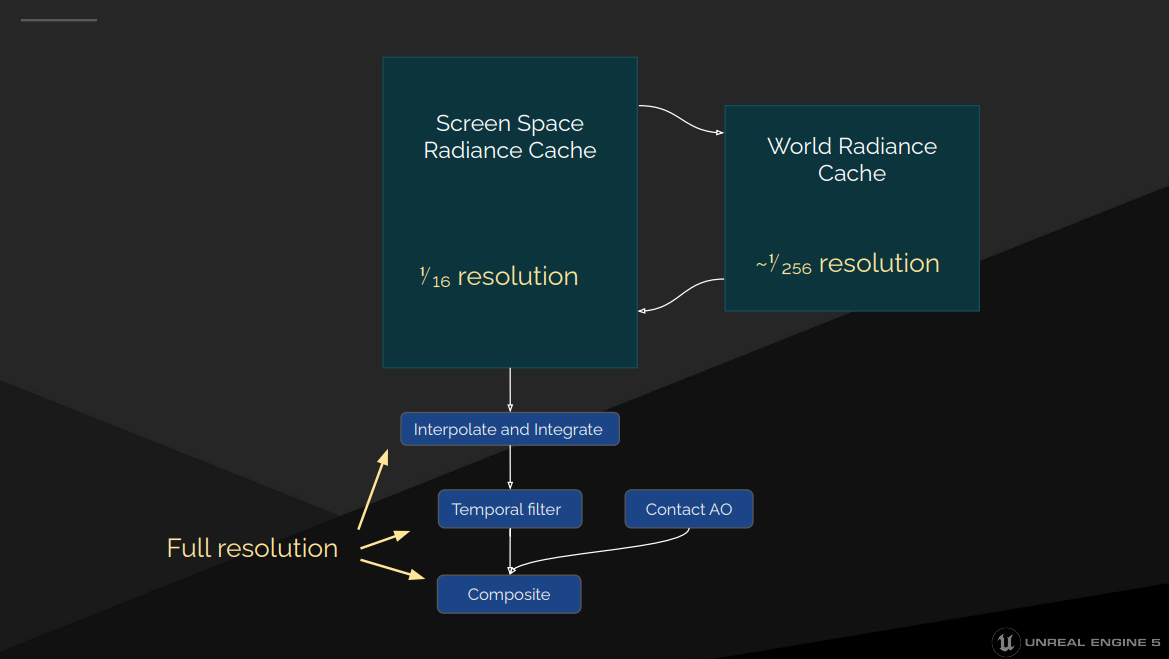
最终聚集技术利用不同距离照明承受的延迟不同这一特点,将辐射分离到不同范围,使用不同技术解决。
通过时间累积利用屏幕空间辐射缓存允许的延迟,通过复用之前帧的所有探针利用世界辐射缓存允许的延迟,而天空光只需要在许多帧中缓慢更新就可以了。
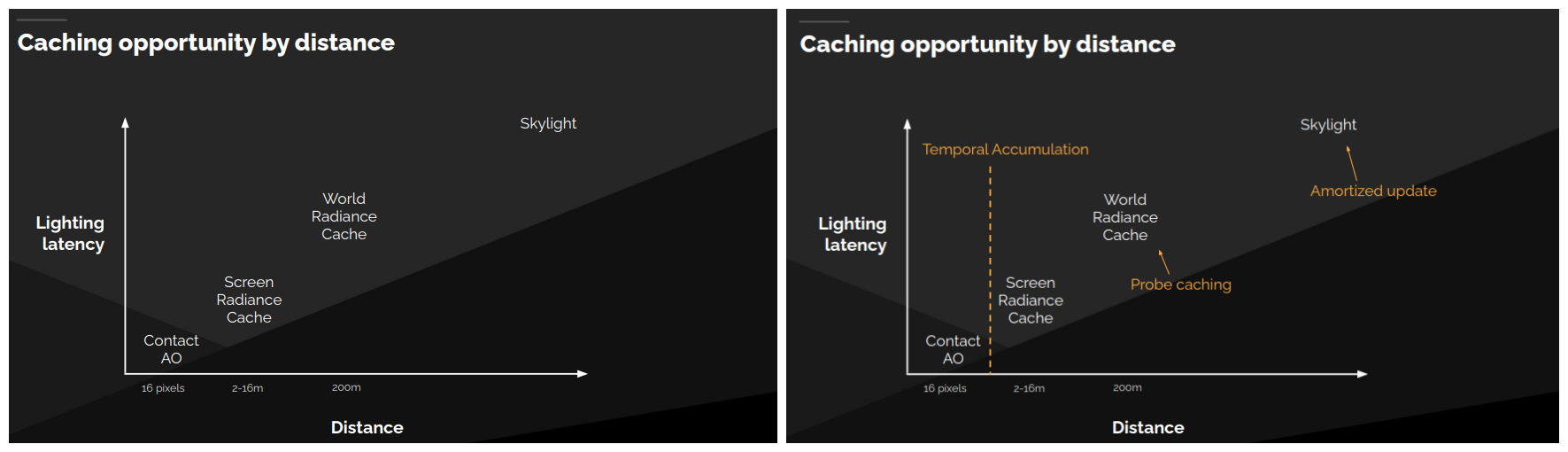
半透明和雾GI挑战
必须支持任意数量的发光半透明层
雾的可见深度范围内的任何地方都需要GI
体积 vs 表面
比不透明的预算小得多
体积最终聚集覆盖了带有探针体积(froxel 网格)的视锥体。
- 追踪八面体探针并跳过通过 HZB 测试确定的不可见探针。
- 在跟踪找到辐射率后,对辐射率进行空间过滤和时间累积以减少噪声。
- 预先集成到球谐辐照度和前向半透明Pass(或体积雾Pass)中,对辐照度进行插值。
为远距离照明使用另一个世界空间辐射缓存。
反射
对于反射,基于 Tomasz Stachowiak 的精彩演讲,使用基于屏幕空间去噪的随机集成。
- 通过对可见 GGX 波瓣的重要性采样生成光线,然后使用光追管道追踪光线。
- 使用空间重用Pass查看屏幕空间邻居并根据它们的 BRDF 重新加权它们。
- 进行时间累积。
- 进行双边滤波以清除任何剩余的噪声。
Dealing with incoherency(P182-P184)
反射管线基于tile,因此能够非常有效地跳过重复使用漫射光线的天空和区域。这很重要,因为管线中有许多分派,在跟踪管道中甚至更多,可以只在屏幕上需要工作的部分进行操作。实际上多次运行整个反射管道,具体取决于场景。至少为不透明运行一次,可能为半透明反射和水反射再次运行它,所以只在需要它的屏幕部分上运行很重要。
半透明反射挑战
- 需要支持任意层数,而且不能直接从像素着色器中追踪。需要在像素着色器之外解决它们,然后插值到像素着色器中。
- 玻璃需要镜面反射,所以不能在那里做任何插值。
为了提供玻璃反射,使用深度剥离将半透明的最前层提取到最小的 GBuffer 中,然后再次运行反射管线,仅在有效像素上运行,并禁用降噪器以减少管线开销。
对于其余层,使用与不透明最终聚集相同的辐射缓存,只需要放置更多的探针。通过以低分辨率光栅化半透明表面来标记新探针,然后在每个像素位置标记所需的探针。然后用任意数量的层光栅化半透明,它们的像素着色器从辐射缓存插值以获得光泽反射。
表现和可扩展性
P191-P196
Nanite / SIGGRAPH course
2021 SIGGRAPH course 里的一节,A Deep Dive into Nanite Virtualized Geometry

目标
Getting on my soapbox for a second, I think as an industry we should be working more on how to make high fidelity games cheaper than we are.
虚拟几何比虚拟纹理要难很多:
- 不仅需要内存管理
- 几何细节直接影响渲染成本
- 几何不是平凡可过滤的
几何表示形式
体素
体素化网格是将矢量图形转化为像素图形的3D等价物,意味着准确率下降。精细采样意味着数据量大大增加。另外,使用体素代替网格意味着要改变整个CG工作流程,纹理、材质、工具等等。
细分表面
对于创作的艺术家来说不能做到所见即所得,渲染成本与艺术家的选择挂钩。
位移贴图
无法处理镂空几何等情况(增加亏格(genus))。
几何图像本质上类似于相对于原点而不是另一个表面的矢量位移图。
点
需要解决连通性等问题。
三角形
Nanite的核心
SOTA三角形渲染管线
UE的渲染器是保留模式设计,场景的完整版本存储在显存中跨帧保留。在事情发生变化的地方稀疏更新。
所有Nanite网格数据存在单个大资源中,可以直接触碰,不需要无绑定资源来这样做。
对于每个视图,都可以在单个调度中确定可见实例。如果只绘制深度,可以在一次DrawIndirect中光栅化所有三角形。
遮挡剔除
将三角形分组为簇并为每个簇构建一个边界框,然后可以根据它们的边界剔除簇。针对HZB使用遮挡剔除,从边界计算屏幕矩形,针对屏幕矩形小于4X4的最低mip进行测试。
如果获取HZB?2 Pass 遮挡剔除:
- 渲染上一帧可见的内容
- 从中建立HZB
- 测试HZB,确认现在可见但在上一帧不可见的内容,绘制任何新内容
可见性与材质解耦
目的是消除光栅化期间材质的切换、过度绘制、密集网格的像素四边形低效率。
使用可见性缓存,将Depth : InstanceID : TriangleID形式的数据写入屏幕。
加载可见性缓存
加载三角形数据
转换顶点位置到屏幕
导出像素重心坐标
对顶点属性插值
作者:在屏幕缓存 IMO 中存储任何顶点属性(如 UV 或法线)不再是可见性缓存,那些我称之为延迟纹理。
通常,可见性缓存方法会将材质评估与着色相结合,但这里写入 GBuffer。这是为了与延迟着色渲染器的其余部分集成。
现在只需要一个draw call绘制所有不透明几何,CPU成本与场景中对象数量无关,材质是逐着色器绘制,但远少于对象。不需要更多次光栅化来减少过度绘制。
簇层次树
次线性缩放
渲染成本应该与屏幕分辨率成比例,而不是场景复杂性。每帧绘制相同数量的簇,而不管有多少对象或它们有多密集。
使用簇层次树规划LOD,运行时找到与所需 LOD 相匹配的树的切割,也就是说同一网格的不同部分可以根据需要处于不同的细节级别。这是基于簇的屏幕空间投影误差以视图相关的方式完成的。如果我们您无法从这个角度分辨出差异,那么父母节点将代替其孩子节点,简化细节。
不需要在内存中存整棵树,可以在任何时候将树的一部分标记为叶子节点,并且不将它之后的任何内容存储在 RAM 中。就像虚拟纹理一样,根据需要请求数据。
但是,当独立的簇做出不同的 LOD 决策并且它们边界处的边缘不再匹配时,就会形成裂缝。可以在简化过程中锁定集群之间的共享边界边,但共享边的簇很多,并且边界上聚集了密集的三角形。好的方法是对簇进行分组,每组做出相同的LOD决策。
其它可能的裂缝解决方案(P40-P44)。
构建树时,首先构建叶子节点(128个三角形),然后对于每个 LOD 级别:
将聚类分组以清理它们的共享边界
将组中的三角形合并到一个共享列表中
简化三角形数量的一半
然后将简化的三角形列表拆分回聚类(128个三角形)
重复此过程,直到有根部只剩下 1 个簇。

合并和拆分步骤使其其实是DAG而不是树。所以从LOD0绘制到根必穿过边,不会有锁定的边界保持锁定并收集碎片。
如何决定对哪些集群进行分组?将共享边界边最多的边分组,因为边界边越少,锁定的边就越少。锁定边越少越好,因为锁定边限制简化步骤减少三角形。
这个问题被称为图划分。图划分算法将图划分为指定数量的分区,使得从一个分区到另一个分区的所有边的总权重(称为边切割成本)最小化。
在这里的例子中,图节点是簇。边连接具有直接连接的相邻三角形的簇。边权重是这些簇之间共享的三角形边的数量。为空间上接近但不连接的簇添加额外的边,以确保图中没有任意分组的岛。该图的最小割边(edge cut)对应于该级别网格中锁定边的最小数量,这基本上是要优化的理想对象。
图划分是一项非常复杂的任务,有一些现有的库可以用来完成它。这里使用流行的METIS库。
如何构建叶子节点?这是一个多维优化问题:
- 为了提高剔除效率,需要最小化聚类边界范围
- 使用光栅化器时,每个簇的三角形数量需要接近但不超过128个
- 顶点数不能超过使用图元着色器的限制
- 最小化簇之间的边界边的数量,再给简化器尽可能多的未锁定边,以允许它完成工作
对第2个维度优化,尽可能解决其它问题。构建叶子节点与构建树的第4步拆分实际上是一样的。
与之前的工作对比(P53)。
简化步骤使用典型的边缘折叠抽取。
未来的工作(P60-P61)。
运行时视点相关LOD
运行时每一帧都需要根据视图选择要绘制的簇。
根据屏幕空间误差决定LOD,一个组的簇做相同的决定。
整个图的LOD决策其实就是切分DAG。切割发生在父节点的误差太高,但子节点的误差小到足以有效绘制的地方(因此需要沿路径的误差函数是单调的)。这是本地操作,可以并行计算。
为了保证运行时簇无缝切换,只选择误差小于1像素的簇绘制。
层次剔除(P69-P74)。
当为LOD进行所有这些剔除时,也应该根据可见性进行剔除。之前的2 Pass 遮挡方法存在一个问题:跟踪先前可见的集合会使一帧到一帧的LOD选择变得复杂,这可能是不同的,并且由于流式传输,上一帧的可见簇可能不再存在于内存中。因此,测试当前选定的簇在最后一帧中是否可见。为了做到这一点,使用前面的变换,根据前一帧的HZB测试它们的边界。
更新后的2 Pass 遮挡剔除:
- 使用先前的变换测试先前的HZB
- 绘制可见内容,保存遮挡以备以后使用
- 然后从深度缓存构建此帧的初始HZB
- 使用此HZB,再次测试我们认为被遮挡的内容
- 绘制现在可见但以前被遮挡的内容
- 最后,从现在完整的深度缓存构建完整的HZB,以便在下一帧中使用。
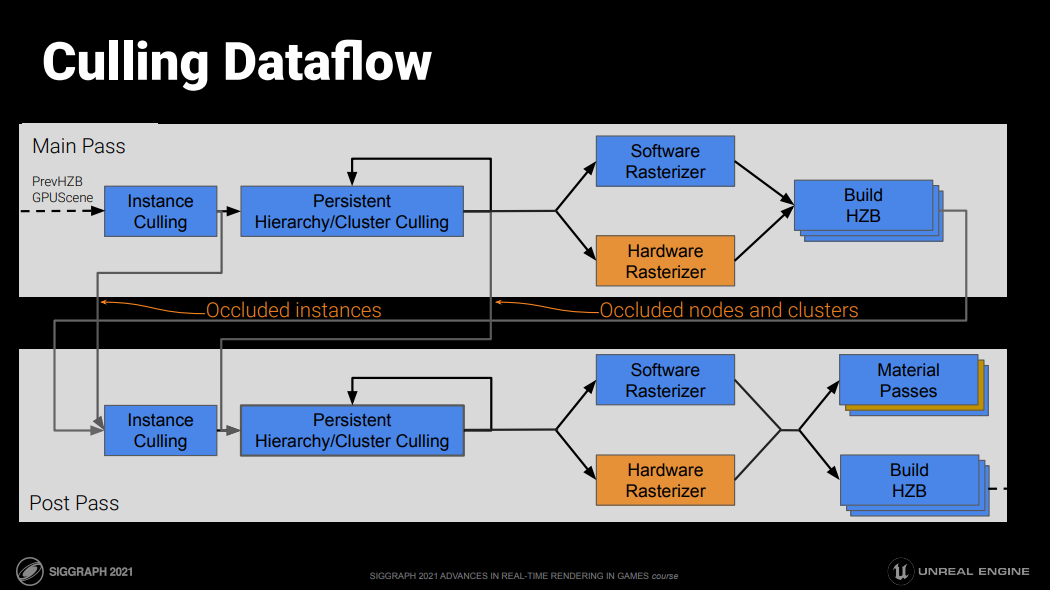
- 使用前一帧的HZB测试来评估遮挡。它从GPUScene的实例开始,以每个实例为基础评估可见性。
- 可见实例转到持久线程分层集群筛选。这同时执行LOD和可见性,并输出可见簇。
- 将其光栅化到可见性缓存。
- HZB是基于刚刚光栅化的内容为当前帧构建的。
- 重复所有剔除阶段,其中基于先前帧信息发现被遮挡的实例、节点和簇用当前帧HZB和当前帧变换重新测试。
- 有了完整的可见性缓存,我们为下一帧构建HZB,并应用延迟材质Pass。
光栅化
因为硬光栅对于Nanite要用的小三角形来说效率很低,使用软光栅。最快的图元着色器实现平均速度比硬件快3倍。对于纯微聚合物情况甚至更多,如果与旧的VS/PS路径相比则更多。
放弃硬光栅会丢失ROP(Raster Operations Units)和深度测试硬件,但仍然需要Z-Buffer。使用64b原子,高位有深度(深度测试),低位有有效载荷(可见簇索引和三角形索引)。
InterlockedMax
| 30 | 27 | 7 |
|---|---|---|
| 深度 | 可见簇索引 | 三角形索引 |
Micropoly 软光栅化器:
在结构上类似于网格着色器。
共享顶点工作,无需任何变换后缓存。
线程组大小为128。在第一阶段,一个线程被映射到簇顶点缓存中的一个顶点。获取顶点位置,对其进行变换,并存储在组共享中。如果超过128个,则获取并转换另一个以支持每个簇最多256个。在第二阶段切换到映射到一个三角形的一个线程,每个簇最多128个三角形。获取该三角形的索引。使用它们从组共享中获取变换后的位置。
计算三角形的边缘方程和深度梯度。对于三角形边界矩形内的所有像素。测试是否在三角形内,如果在三角形内则写入像素
软光栅三角形长度小于32像素的任何簇。对大三角形等不会更快的情况使用硬光栅。DirectX对光栅化规则有非常严格的规范。我们可以精确匹配硬件,这意味着软光栅簇和硬光栅簇之间没有像素裂缝。
过度绘制(P93)。
小实例优化(P95-P97)。
延迟材质评估
可以绘制一个覆盖屏幕的四边形,解码可见性缓存Depth : InstanceID : TriangleID并评估材质像素着色器,就像它在光栅化期间绑定一样。
VisibleCluster => InstanceID, ClusterID
ClusterID + TriangleID => MaterialSlotID
InstanceID + MaterialSlotID => MaterialID
阴影
真实几何体和法线贴图之间最大的视觉差异通常来自于详细的自阴影。
Nanite 支持正常的阴影贴图绘制,但这种新架构支持以前不实用的新技术。现在对所有内容都使用 16k 阴影贴图。根据光的类型,可能会有一个或多个阴影贴图。
如果阴影贴图的那个区域没有投射到屏幕上的任何东西上,就不会绘制它。与优化阴影渲染的更常见方法相比,不仅剔除了光栅化工作,甚至不为不打算采样的阴影贴图空间分配内存。
流
几何体的虚拟内存类比在概念上与虚拟纹理非常相似,但细节不同、存在一些独特的挑战。类似之处在于GPU在发现质量不足时请求数据,而CPU通过从磁盘加载数据来异步完成这些请求;不同之处在于,当加载和卸载数据时,需要确保它始终是整个DAG的有效切割,几何体中才不会出现裂缝。
为避免内存碎片,我们希望使用固定大小的页面,但这也意味着我们必须在每页中容纳可变数量的几何图形。为了避免渲染不正确,用至少高于组的粒度填充固定大小的页面。在决定将哪些组放在同一页面上时,会考虑 DAG 中的空间局部性和级别。这些都是为了尽量减少运行时可能需要的页面数量。
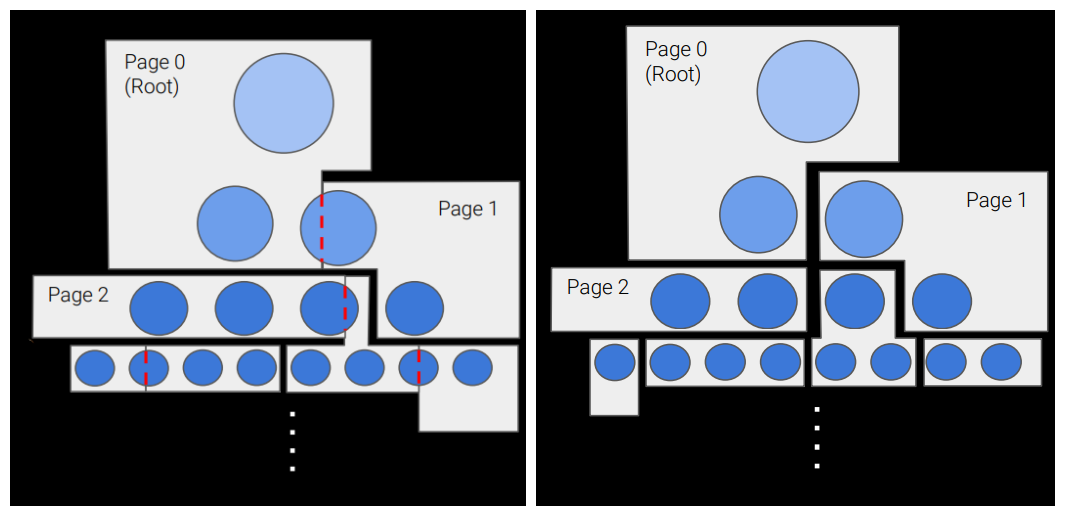
第一个页面,即根页面,总是驻留的,并且包含页面中可以容纳的尽可能多的 DAG 顶部。总是有根页面意味着我们总是有东西要呈现。常驻页面存储在 GPU 上的一个大 ByteAddressBuffer 中。
组可能非常大,因此用整个组填充页面会导致大量松弛。以簇粒度将组分成多个部分。 因为在加载其所有兄弟节点之前无法绘制集群,所以拆分组仅在加载其所有部分时才被视为活跃的。
压缩
对于Nanite,实际上有两种压缩的几何格式。它们表示相同的数据,但针对不同的目标进行了优化。
内存表示是渲染代码在光栅化期间和延迟材质过程中直接使用的表示。这需要在解码和随机访问时接近即时,因为可以从可见性缓存查找中请求任何三角形。这里的目标是降低流媒体池所需的内存。即使我们有足够的内存来烧录,将更多的数据放入缓存也意味着更少的缓存未命中,这意味着更少IO和弹出的机会。
磁盘表示是磁盘中的数据表示,当数据流进来时,它会被转码为内存表示。这种格式不需要随机访问,因为流传输的频率低于渲染,所以我们可以在这里提供更先进的技术。